
计组-实验-Pre
虚拟机
基本命令
shell中,输入命令的格式为<命令名称><参数1><参数2><参数n>...。其中,“命令名称”有两种类型:系统命令和路径命令。
系统命令直接由命令名表示。如,cd和ls,vcs皆为系统命令。
路径命令的格式则为路径/程序文件名,程序可以位于任何地方,不一定是系统程序目录。
例如,用户主目录中有hello.sh文件。在shell中输入~/hello.sh或./hello.sh,即可执行这个文件(注意后者只能在用户主目录下执行)。
只有特定的文件(例如脚本、可执行文件)才能被执行,文本文件、Verilog源代码文件等都是不能执行的。
ls:查看当前目录下的所有文件。cd:进入其他目录。date:查看当前日期时间。cp<源文件名><目标文件名>:复制文件。rm<文件名>:删除文件。echo<文本>:原样显示文本。cat<文件名>:查看文件内容。
主目录
~是一个缩写,代表用户的主目录(home)。在表示文件路径时,我们常用这个缩写,例如~/VCS-Example表示/home/co-eda/VCS-Example。
目录(directory)又称文件夹(folder),这两者一般表示相同的含义。
当前目录
Linux中,有两个特殊的目录:
.(一个点)表示当前所在目录;..(两个点)表示当前目录的上一级目录。
执行cd.不会有任何作用;执行cd..可返回上一级目录。
上面的“目录名”是相对路径,即相对于当前目录的路径。cd命令也可直接到达绝对路径。例如,无论当前目录在何处,输入cd~都可到达用户主目录下。
若觉得使用cd命令进入目录太麻烦,也可在文件管理器中打开想进入的地方,然后按下F4键,即打开终端并直接进入该目录。
Logisim
Logisim提供图形界面,以鼠标拖拽的形式可以新建部件以及进行部件间连线。
数字电路中最基础的内容就是逻辑电路门。普通的电路门如与门、或门、非门(真值表)。
组件
在数字电路中,加法器是一种用于执行加法运算的数字电路部件,是构成电子计算机核心微处理器(CPU)中算术逻辑单元(ALU)的基础。在这些数字电路系统中,加法器主要负责计算地址、索引等数据。除此之外,加法器也是其他一些硬件,例如二进制数乘法器的重要组成部分。
尽管可以为不同计数系统设计专门的加法器,但是由于数字电路通常以二进制为基础,因此二进制加法器在实际应用中最为普遍。在数字电路中,二进制数的减法可以通过加一个负数来间接完成。为了使负数的计算能够直接用加法器来完成,计算中的负数可以使用补码来表示。
组件图标
下面是Logisim中
Wiring(线路)组件

Gates(逻辑门)组件
Plexers(复用器)组件

Arithmetic(运算器)组件

Memory(存储)组件

Input/Output(输入/输出)组件

Base(基本)组件
Tunnel
用于简化布线,省略了中部的连线,是一种抽象
tunnel通过标签名来作为数据两端的联通,只能有一个输入,但可以有多个输出,需要修改其databits
Pull Register 上下拉电阻
只有当该点的值是x时,上下拉电阻将其连接的电线拉向其属性中指示的值0,1,X。
如果原先有值了,由于上下拉效果较弱,不影响原先的值,即只对不定值X进行上下拉
时钟
时钟的本质是按照固定频率输出高低点位。Logisim中对时钟的模拟是相当不现实的:在真实的电路中,多个时钟会漂移,永远不会同步移动。但在逻辑上,所有的时钟都以相同的频率改变。
一个时钟只有一个引脚**,**为位宽为1的输出,其值代表时钟的当前值。
Power电源/Ground地线
输出位全为1/0,与上下拉不同的是会与原先有值形成冲突
Transistor晶体管
分为P型和N型:
| 真值 | source | gate | output |
|---|---|---|---|
| P | 0 | 0 | 0 |
| P | 1 | 0 | 1 |
| P | 0 | 1 | x |
| P | 1 | 1 | x |
| N | 0 | 0 | x |
| N | 1 | 0 | x |
| N | 0 | 1 | 0 |
| N | 1 | 1 | 1 |
可以看出P型和N型中gate的作用相反。P型在低电平时导通,N型在高电平时导通
位扩展器
将n位输入扩展为m为输入
- n<=m:对于高位,有四种补全方式可以选择
- 1/0:补充1/0
- sign:根据额外的输入决定,补额外的输入
- input:根据n位中的最高位补全
- n>m:直接截断
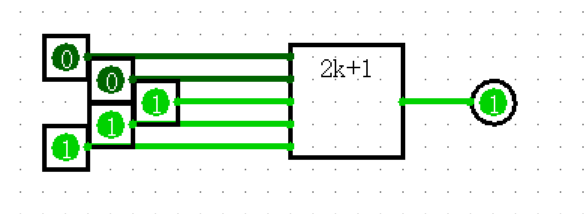
n位异或门
对于每一位,当且仅当只有一个1时才输出1,这和一般的n输入异或不一样:奇数个1时为真
奇校验/偶校验
对于多个输入的每一位,有奇数/偶数个1时在对应位输出1
Controlled Buffer 受控缓冲器/三态门
对于控制位,控制位输入为1时输出为输入,控制位为0时不论输入,全部输出为x,可以用上下拉电阻基于默认值。
相当于一个有开关的通路,只有开关打开时才能通过
Multiplexer 多路选择器
对于n型的多位选择器,有个可能的输入,通过两个辅助输入决定唯一的输出值
第一个辅助输入决定输出哪一个输入的值,第二个辅助输入 为使能端,一定要为1,可以用常量

Demultiplexer 解复用器
唯一输入,多个输出,其他和多路选择器一致。不被选择的输出位输出0
MUX多个输入,唯一输出;Demu唯一输入,多个输出。
都有一个决定是否输出的额外输入和另一个决定选择第几个输入/输出的额外输入
Decoder 译码器
无输入,有输出。一个输入决定是否输出,另一个输入决定哪一个输出1
译码器最大的功能在于将二进制编码转换为相应的独热码(one-hot),如101的3位二进制编码作为输入就会被转换成00100000的8位独热码作为输出。因而该元件得名译码器。

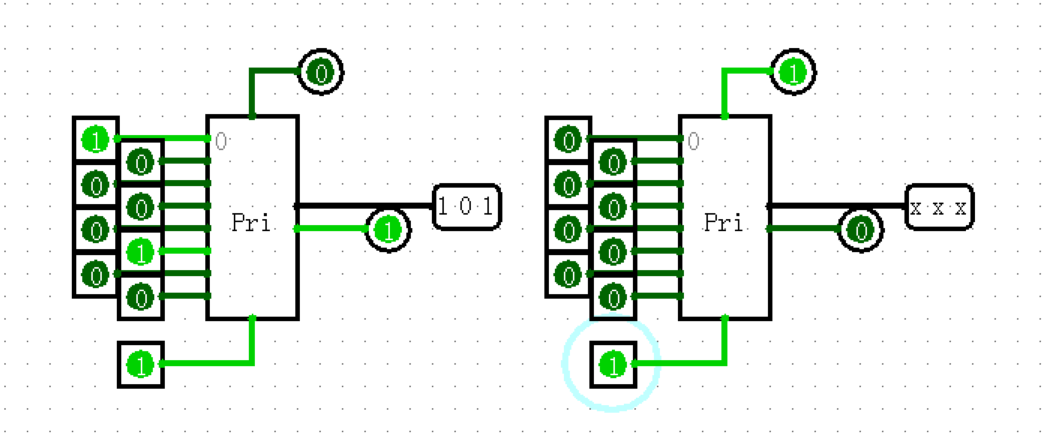
Pirority Encoder 优先编码器
组件在其左边有多个输入,第一个输入编号为0,从上往下编号。该组件寻找值为1的输入的编号,并输出值最大的编号。
例如,如果输入端编号为0、2、5和6的输入都是1,那么优先级编码器将输出110(也就是编号6的二进制表示)。如果没有输入为1,或者组件被禁用,那么优先级编码器的输出是浮动的。

使能端即为开关,可缺省。当使能端为1时。如果输入中无1,则上方输出为1,若有1,则右下输出为1
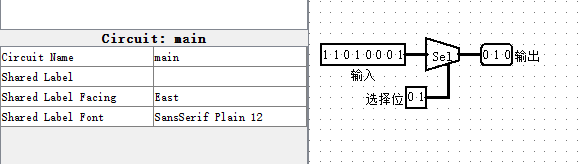
Bit Selector 位选择器
将输入均分为m位,输出第n位。由输出二决定输出中被均分输入的哪一份
可以代替移位+位扩展的截取效果,简化电路
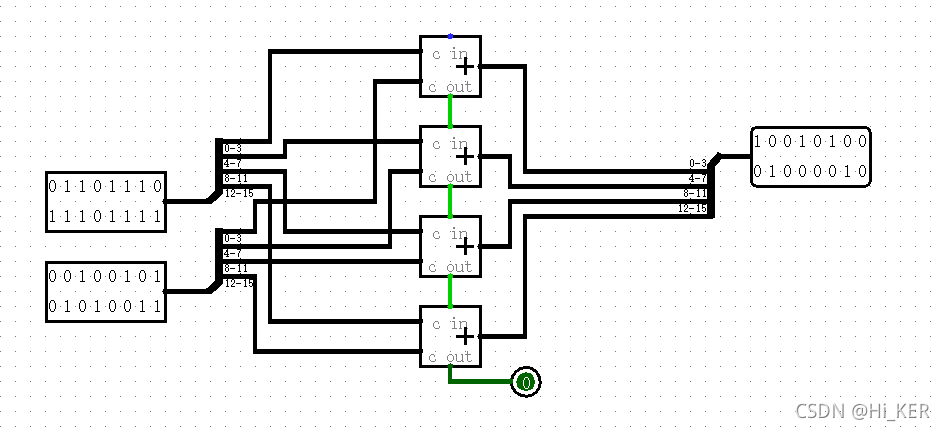
加法器/减法器
有进位的区别,上方为进位输入,即最后结果+1;下方为进位输出,若本次两指相加后溢出,则输出为1
一个加法器级联的示例:
对于减法器,则上方输入表示最后结果-1;若减后溢出,则下方输出为1,输出为补码
乘法器
上方输入为需要相加的进位值,输出为取(当前能输出最大值+1)模后的结果,下方输出为除(当前能输出最大值+1)后的结果
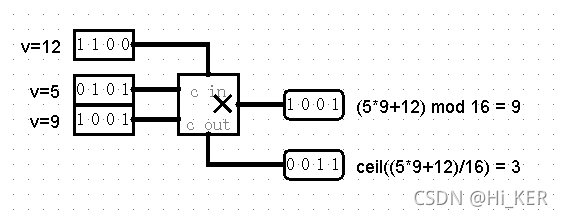
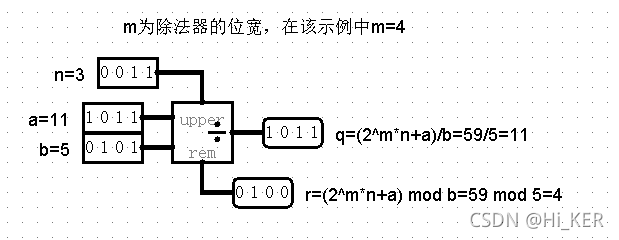
除法器
除法器将左边输入的两个值相除,在右边输出商。组件的设计便于它与其他除法器级联。
如果除数为0,则不进行除法运算(即假设除数为1)。
除法器实际上执行无符号除法。商总是一个整数,且商*除数+余数=被除数。
上方输入为被除数在位宽之前的数
Negator 求补器
求补码:取反+1
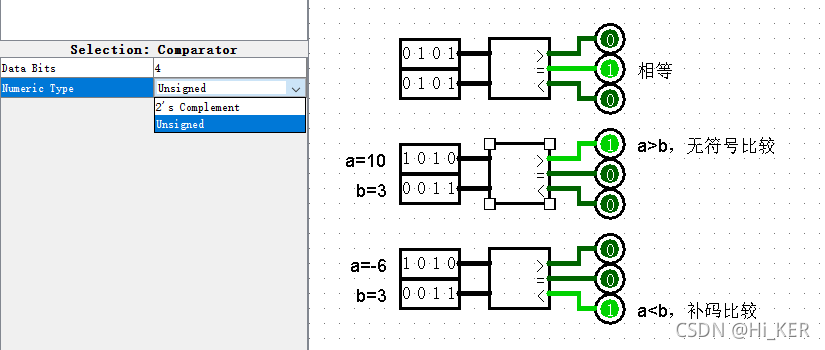
比较器
比较两个值(无符号值或两个补码值,可选)的大小。比较器有3个输出,通常,其中一个输出为1,另外两个输出为0。
比较从每个数字的最有效位开始,并并行地向下进行,直到找到两个值不一致的位置。但是,如果在下降过程中遇到错误值或浮点值,则所有输出将匹配该错误或浮点值。
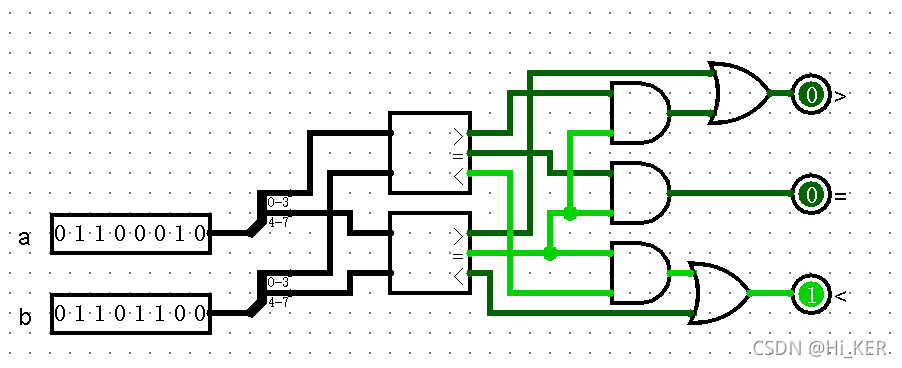
比较器可级联。
简单的比较器级联示例:
移位器
-
逻辑左移
数据中的所有位向左移动
dist位,底部空出的位用0填充。例如,11001011逻辑左移两次就是00101100(之前的右边两位丢弃) -
逻辑右移
数据中的所有位向右移动
dist位,左端空出的位用0填充。例如,11001011逻辑右移两次就是00110010(之前的左边两位丢弃) -
算术右移
数据中的所有位向右移动
dist位,左端空出的位用数据中最高位重复填充。例如,11001011算术右移两次就是11110010(之前最高位为1,所以用1填充) -
循环左移
数据中的所有位都向左移动
dist位,左边被“挤出去”的位填充到右边空出的位。例如,将11001011循环左移两次就是00101111。 -
循环右移
数据中的所有位都向右移动
dist位,右边被“挤出去”的位填充到左边空出的位。例如,将11001011循环右移两次就是11110010。
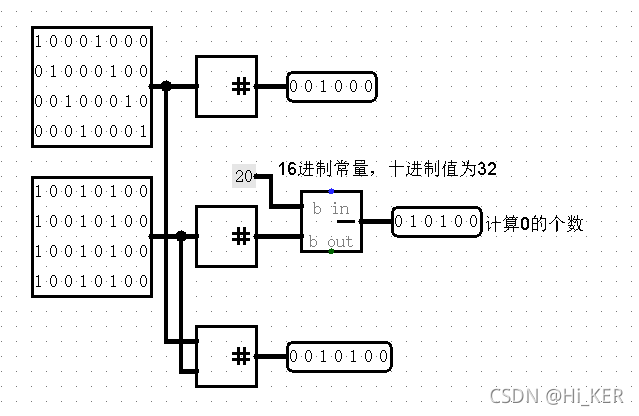
Bit Adder 逐位加法器
逐位加法器计算输入中有多少位是1,并输出中1为的位的数量。
右侧可以有多个输入,统计总共的1的数量
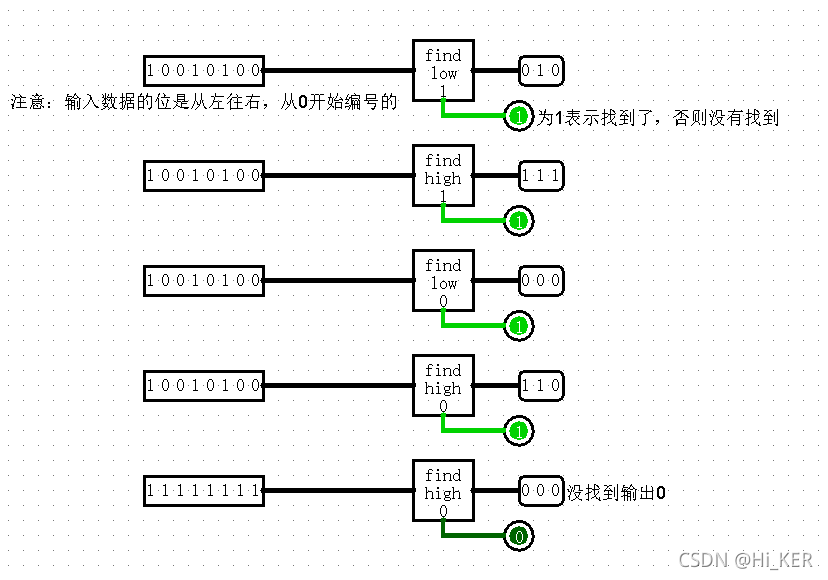
Bit Finder 位查找器
寻找高位/低位的0/1
触发器总体介绍
触发器可以存储单比特数据。右边输出的Q值根据左端的输入进行变化(时钟信号)。
触发器接受时钟信号,输出的信号(称为状态)改变。将触发器原来的状态(即触发器接收输入信号之前的状态)称为原态或现态,用表示。改变后的状态(即触发器接收输入信号之后的状态)称为次态,用表示。
具体来说,当时钟输入(在每个触发器时钟输入端口用三角形标记)从0上升到1(或其他配置)时,触发器被触发,Q值可能会根据输入发生变化。一般来说,触发器常用的触发方式为时钟上升沿触发和下降沿触发,可在设置中选择需要的触发方式。
异步复位(固定触发器值为0)
当且仅当端口输入为1时,触发器的值就固定为0。
异步:与当前时钟输入值无关。只要该端口输入是1,其他输入就没有影响。
异步设置(固定触发器值为1)
当且仅当端口输入为1时,触发器的值就固定为1。
异步:与当前时钟输入值无关。只要该端口输入是1,其他输入就没有影响,除了具有更高优先级的异步复位。
使能端(启用时钟信号)
当该端口输入值为0时,时钟触发被忽略,Q输出保持不变。当此输入为1或未定义时,时钟触发被启用。
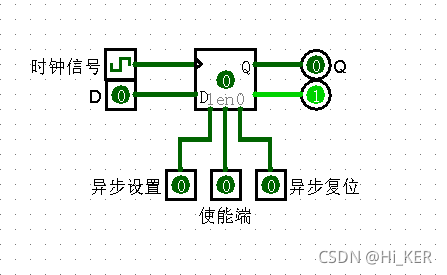
异步复位、异步设置、使能端3个端口均可以不连接输入,触发器也可正常工作。
使用Poke工具点击触发器可改变存储在触发器中的值,除非异步设置/复位输入当前锁定了触发器的值。
D Flip-flop D触发器
时钟触发时,D触发器存储的值变为输入值
T Flip-flop T触发器
时钟触发时:
- 如果输入是1,则Q不停变化,在0和1之间切换
- 如果输入是0,则Q保持不变,Q可能是0或1
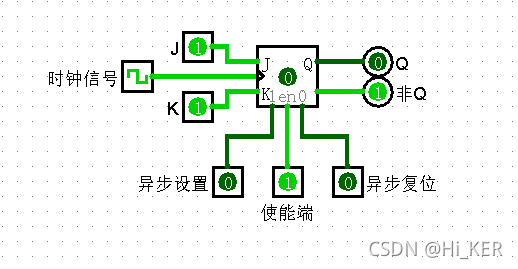
J-K Flip-flop JK触发器
J为jump信号,k为kill信号
JK触发器在触发时值根据下表的变化:
| J | K | Q |
|---|---|---|
| 0 | 0 | |
| 0 | 1 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | (来回切换) |
S-R Flip-flop SR锁存器
R为reset,S为set
最基本的锁存器
| S | R | Q |
|---|---|---|
| 0 | 0 | |
| 0 | 1 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 未知,但在logisim中表现为不变 |
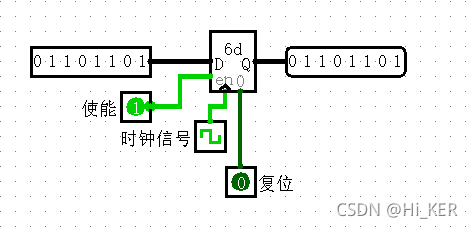
Register 寄存器
寄存器存储单个多位值,该值以十六进制形式显示在其矩形内,并在其输出端输出。
在使能端开启后,当时钟信号输入满足寄存器触发条件时,存储在寄存器中的值就会在该时刻改变为D输入的值。
时钟信号指示寄存器储存值发生改变的确切条件是通过触发属性配置的,Logisim中一般有时钟上升沿和下降沿,高电平和低电平这四种触发方式。
Reset输入异步复位,将寄存器的值重置为0(全部为0),也就是说,只要Reset为1,寄存器值就固定为0,不管时钟和输入是什么。
Counter 计数器
计数器持有单个值,其值会在Q端口输出。每次时钟输入(输入端口用三角形标记)根据触发属性触发计数器。
计数器的值将根据元件左边两个输入load和count,左边有3个输入端口,最上方的输入端口称为load,中间的称为D,最下方的称为count
| load | count | 触发情况 |
|---|---|---|
| 0或x | 0 | 计数器值不变 |
| 0或x | 1或x | 计数器值++ |
| 1 | 0 | 计数器载入D输入值 |
| 1 | 1或x | 计数器值减少 |
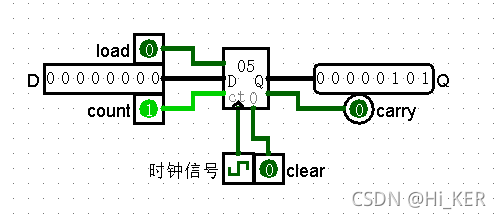
计数范围可以使用“最大值”属性配置。当计数器达到这个值时,下一个增量将让计数器值回到0;如果计数器值0,那么计数器值减少操作将把计数器设置为它的最大值。
除了输出Q外,该组件还包括一位输出:carry(进位)。当计数器达到最大值时,当load和count输入指示计数器在下一步该增加时;或者当计数器为0时,load和count输入指示计数器在下一步该减少时,carry值为1。
溢出时操作
-
Wrap around重新计数
-
递增时,下一个值是0
-
递减时,下一个值时最大值
-
-
Stay at value保持当前值
-
递增时,保持最大值不变
-
递减时,保持0不变
-
-
Continue counting继续计数
- 计数器继续递增/递减,保持数据位属性提供的位数
-
Load next value加载下一个值
- 下一个值从D输入中加载
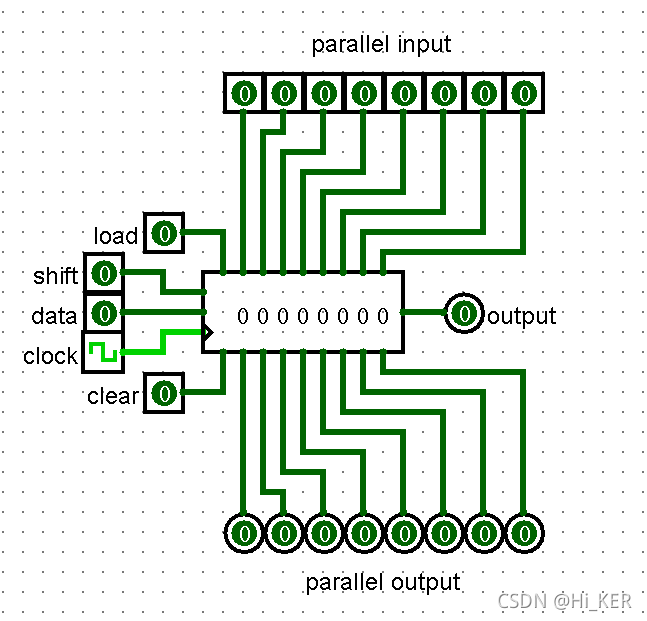
Shift Register 移位寄存器
-
Clear清空(输入引脚,位宽1)
将所有阶段异步重置为0,也就是说,只要clear输入为1,所有输出值都固定为0,而不管时钟和输入是什么。
-
Shift移位(输入引脚,位宽1)
当断开或输入为1时,所有级通过时钟触发右移左边空出的位由data填充,但如果输入是0,则不会右移。如果Load输入为1,则忽略此输入。
-
Data数据(输入引脚,位宽匹配Data Bits属性)
在推进阶段时,在此输入中找到的值被加载到第一阶段。
只在启用Parallel Load属性时存在的引脚:
-
Load加载(输入引脚,位宽1):加载上方输入的各位
-
Parallel Input并行输入(输入引脚,共Number of Stages个,位宽匹配Data Bits属性)
当Load输入为1时,其他在上方的引脚(即并行输入引脚)输入值在时钟触发是被加载到移位寄存器中。0或断开时,不会加载。
-
Output串行输出(输出,位宽匹配Data Bits属性)
输出存储在最后阶段的值
-
Parallel Output并行输出(输出引脚,共Number of Stages个,位宽匹配Data Bits属性)
输出对应的每个阶段(Stages)的值
Random Generator 随机数生成器
遍历一个伪随机数序列,当启用时,每次时钟被触发时,该序列将前进到序列中的下一个数字。从技术上讲,用来计算伪随机序列的算法是一个线性同余生成器:从种子开始,下一个的数字就是:.下一个值是用相同的计算方法从计算出来的,以此类推。从组件中看到的值是其位宽属性配置的低阶位。
除了时钟输入,组件还包括一个使能输入,当使能为0时,该时钟输入将被忽略,以及复位输入,该组件的值将异步重置为初始种子。初始种子是用户可配置的。如果它被配置为0(这是默认值),那么种子将基于当前时间;当指示通过重置输入端口进行重置时,组件根据新的当前时间计算一个新的种子
RAM:随机存取存储器
RAM组件是Logisim内置库中最复杂的组件,最多可存储16,777,216个值(在地址位宽度/Address Bit Width属性中指定),每个值最多可包含32位(在数据位宽度/Data Bit Width属性中指定)。RAM可加载和存储数据。
几个引脚
- sel(Chip Select)(输入引脚,位宽1):此输入启用或禁用整个RAM模块,基于值是1,浮动还是0。该输入主要用于有多个RAM单元的情况,在任何时候只有一个RAM单元是启用的
- clr清除数据/Clear(输入引脚,位宽1):当该值为1时,RAM中的所有储存值都固定为0,不管其他输入是什么
RAM组件支持三种不同的接口,这取决于数据接口(Data Interface)属性:
三态门很关键
一个同步加载/存储端口(默认)
该组件在其右侧包括一个单独的端口,用于加载和存储数据。它的执行取决于标签为ld的单比特输入,ld是load data(加载数据)的缩写。
ld=1(或浮动)表示以A指定的地址加载数据到D输出,ld=0表示存储在D端口上输入的数据。
要在组件之间传输数据,将需要使用三态门组件,如下图所示。
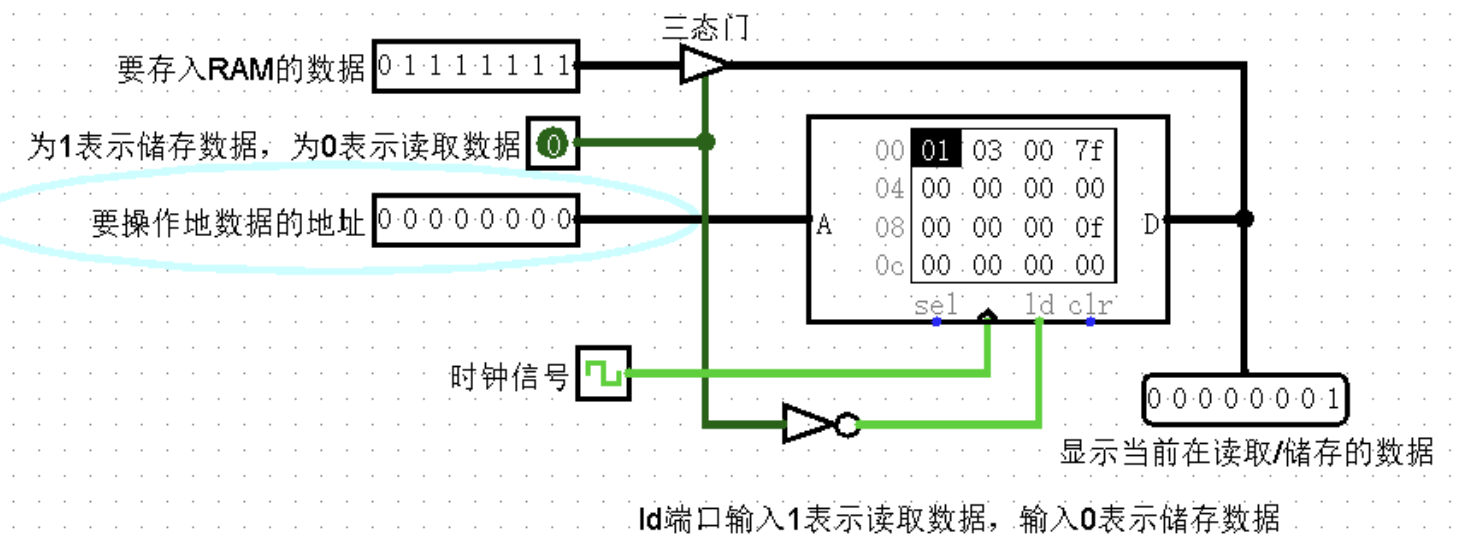
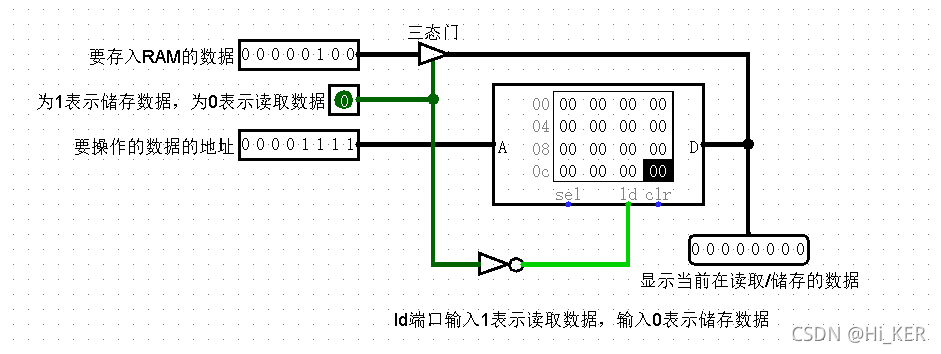
一个异步加载/存储端口(消除了时钟信号)
这和上面一样,只是没有时钟输入。当ld输入为0时,在数据总线上的值被存储到存储器中。当ld输入为0时,地址或数据发生了变化,则会发生额外的存储。ld为输入为1时,D端口输出当前地址数据的值。
这个选项被用于着更接近地模仿许多可用的随机访问存储器的接口。
分离的加载和存储端口(消除了三态门)
提供两个数据端口:一个在西面用于存储数据,另一个在东面用于加载数据。该选项消除了三态门的必要性,因此更易于使用。
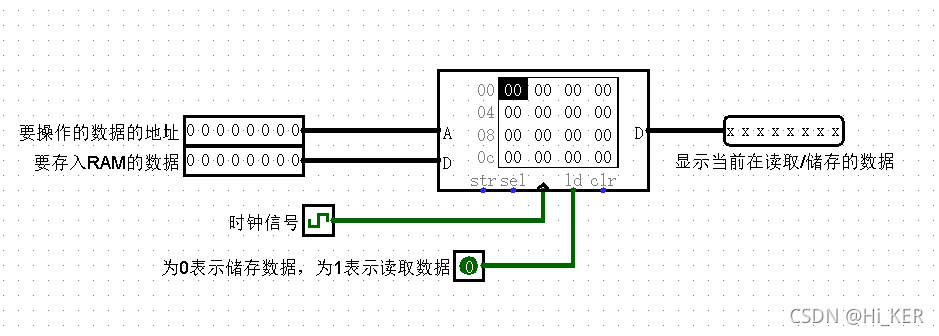
其中仅在该状态出现的str储存/Store引脚(输入引脚,位宽1):此输入仅在为Data Interface属性选择了“分离的加载/存储端口”时出现。当它为1或浮动时,时钟脉冲将导致将左边D的数据存储到RAM中(假设sel输入也是1或浮点)
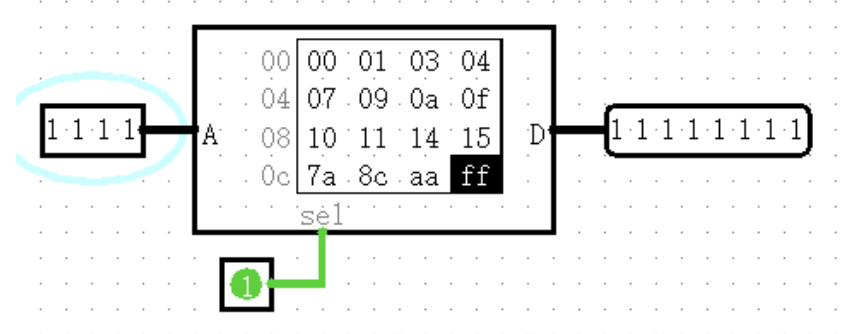
ROM只读存储器(Read-Only Memory)
电路可以访问ROM中的储存值,但不能改变它们。用户可以通过Poke工具交互修改单个值,或者用户可以通过菜单工具修改整个内容。
ROM组件的当前内容是作为组件的属性存储的。因此,如果一个包含ROM组件的电路被使用了两次,这两个ROM组件都持有相同的值。也因为这种行为,ROM的数据存储在Logisim创建的文件中。
时序电路
一个电路,使其输出结果不仅与当前的输入有关,还可能与电路之前的输入有关(即电路能记住之前的状态)
时钟是时序电路中最关键的组件,时钟按照一定的频率输出高频低频信号,所有的时钟都按照相应的频率输出信号。
时钟沿
时钟上升沿:数字时钟电路中,数字电平从低电平(数字0)变为高电平(数字1)的那一瞬间叫作上升沿。
时钟下降沿:数字时钟电路中,数字电平从高电平(数字1)变为低电平(数字0)的那一瞬间叫作下降沿。
寄存器存储的值,就是在时钟上升沿发生变化的。
复位信号
寄存器会接受一个外部传入的、可以将自身存储数据清零的信号。寄存器的复位信号有两种,分别是同步复位和异步复位。
同步复位:复位信号只有在时钟上升沿到来时,才能有效。也就是说,同步复位操作永远发生在时钟上升沿,即便复位信号提前到来,也无法立刻完成复位操作。
异步复位:无论时钟沿是否到来,只要复位信号有效,就对系统进行复位。
关键路径是指同步逻辑电路中,组合逻辑时延最大的路径。
寄存器
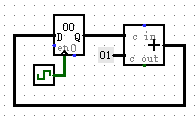
对于这样的电路,实现了在每个时钟周期内寄存器存储的值++。本电路看似短路,实则利用了时延的特性。
寄存器本质就是一个D触发器,它是由两个D锁存器构成的。
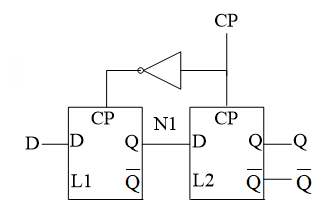
D锁存器的功能是当CP为高电平时,Q赋值为D。当时钟低电平时,左侧的锁存器将储存值D赋值给N1,当时钟高电平时,右侧的锁存器将N1赋值给Q。
**这个世界上本没有上升沿赋值,只有高低电平赋值。**通过这样两个D锁存器结合形成的D触发器,宏观上就表现为了上升沿的赋值。
先(时钟低电平时)打开第一道关卡,堵第二道关卡,让船(输入数据)到中转站(N1),然后堵上第一道关卡,开第二道关卡(时钟高电平时),让船只通过。
由于两个过程交替进行,宏观上就变成了,时钟在上升沿时,数据进行赋值。
step simulation
Simulate 菜单中有一项 Step Simulation,这个选项在平时我们并不常用,但使用它能看到 Logisim 对电路仿真的细节,所以有时对调试是很有帮助的。这个选项在 Simulation Enable 被选中时是不可用的,所以使用前记得关闭 Simulation Enable。
每当我们点击一次 Step Simulation,电路就会向前仿真一步。注意这里的一步并不是时钟改变一次,而是 Logisim 进行了一次它仿真的最小粒度。

如这个电路,因为电路中电流传播需要时间的原因,会有一个奇怪的现象:这个电路正常来说应该始终输出 0,但在 Logisim 中,其输入每改变两次,输出就会改变一次。
本质是因为因为非门增加了传播时间,使得与门有机会输出高电平信号,因而对于D触发器是上升沿,载入输入D=1。
一道好题
黄小板同学暗中观察了公司负责人很久,觉得他搭建的电路性能实在太差,他提出只需要 64 个周期就能计算出 32 位无符号整数能表示的最大数位置上的斐波那契数的(最后 32bit),在完成搭建这样的电路后,公司负责人五体投地,宣布给黄小板开出了东门烤串无限量供应的实习工资,从此黄小板每日吃串,终于吃成了黄老板…
那么,这个电路是什么样子的呢?
注意:这道题是一个对你的挑战,需要一定的算法和工程能力,请谨慎思考,大胆尝试!
使用 Logisim 搭建一个根据输入序号计算对应序号斐波那契数的电路并提交。
-
-
输入: N(32bit无符号数)
-
输出: Nth(32bit无符号数,表示第 N 个斐波那契数)
-
文件内模块名: main
-
测试电路图:
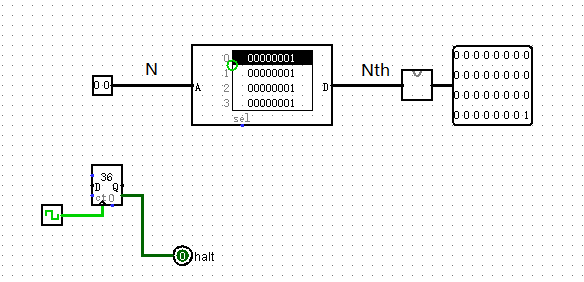
-
测试要求:在 64 个周期内计算出结果并稳定输出,在结果未计算出之前输出端口输出 0。
-
HINT:矩阵乘法的快速幂
解答:https://blog.csdn.net/JeremyZhao1998/article/details/108938046
这篇博客写的非常不错,深入浅出
Verilog与工具仿真
Verilog 模型可以描述实际电路中不同级别的抽象。所谓不同的抽象级别,是指同一个物理电路,可以在不同的层次上用 Verilog 语言来描述它。在这里,不同的层次可以理解为:电路的某个功能部件是由更小的、功能较为简单的部件连接组合而成的。
复杂数字逻辑电路和系统的层次化、结构化设计意味着硬件设计方案的逐次分解。
常用的硬件系统设计方法主要分为自顶向下设计以及自底向上设计两种:
-
在自顶向下设计(Top-down design)当中,从顶层开始,进行功能划分和结构设计,重写行为建模至结构建模,直到可使用元件/原语(primitive)进行描述;
-
从底向上设计(Bottom-up design)当中,从简单门器件出发(通常复用已制造的标准基本单元模块),逐层搭建更复杂的模块,直到实现顶层行为要求。
结构化建模
在 Verilog 中,结构化建模的主要表现形式为实例化(instantiate)。通俗来讲,实例化就是利用某个模板所创建一个其所对应的实体的过程。我们想要使用一个元件前,需要对其进行实例化。在实例化的同时,我们需要指定模块输入输出端口与对应的信号。
对电路元件进行实例化的最常见语法是:
1 | 模块名 实例名(端口信号映射); |
其中,端口信号映射的格式也有两种:
- 位置映射:
模块名 实例名(信号1, 信号2, ...),其中信号 n 对应被实例化模块声明时排在第 n 位的端口。 - 名映射:
模块名 实例名(.端口名a(信号1), .端口名b(信号2), ...),其中信号 n 对应其前的端口名。
值得注意的是,在实例化元件时,wire 类型信号可以被连接至任意端口上,但 reg 类型的信号只能被连接至元件的输入端口上。在声明元件时,我们可以将任意端口声明为 wire 类型,但只能将输出端口声明为 reg 类型,否则会出现问题。
下面来看一个例子:
1 | module Adder( |
对应的电路图如下所示:
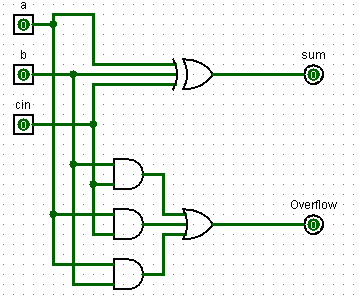
模块的端口input、output默认为wire型,可以直接声明为reg型:output reg c
模块的内部典型结构
假设已经有一个定义好的模块Sample,输入输出定义如下:

我们在设计的过程中,需要引用上述模块,其中变量x对应管脚a,变量y对应管脚b,变量z对应管脚c,reset管脚没有使用。即可以使用:Sample uut(.b(y),.a(x),.c(z));
实现电路的行为级描述
使用行为级描述设计电路时,主要描述电路输入信号和输出信号间的逻辑关系,关注电路“干什么”而不是“怎么做”。低层次内部结构和实现细节等的考虑,以及将其转化为物理电路的过程,都由软件自动完成。
行为级描述的方法一般有两种:
- 利用连续赋值语句
assign描述电路。 - 利用
initial结构、always结构和过程控制语句描述电路。
连续赋值语句 assign
一种很重要的行为级描述就是连续赋值语句,其常见形式为:
1 | assign signal = expression; |
其中 signal 必须是 wire 型数据,而 expression 则是由数据和运算符组成的表达式。
assign 语句的作用是将右侧表达式的值持续性的赋给左侧的信号,一般用于描述一个信号是如何由其他信号生成的。所谓持续性,指的是当右侧表达式中的变量发生变化时,左侧信号的值也会随之变化。
assign 语句非常适合简单的组合逻辑的描述,经常与三目运算符配合使用。一般来说,assign 语句综合出来的电路是右侧表达式化简后所对应的逻辑门组合。
过程控制语句与有关结构
我们可以把电路的当前状态(如果有)和电路的输出抽象为一些变量。通过描述不同条件下对这些变量的变化规律来描述电路,这就是利用过程控制语句与有关结构进行的行为级描述。
变量,是指reg型数据。reg 类型数据只是一个变量,用途是方便的描述,并不一定对应一个真实电路中的寄存器
常见数据类型
wire型
wire 型数据属于线网 nets 型数据,通常用于表示组合逻辑信号,可以将它类比为电路中的导线。它本身并不能存储数据,需要有输入才有输出(这里输入的专业术语叫驱动器),且输出随着输入的改变而即时改变。一般使用 assign 语句对 wire 型数据进行驱动。在访问时,可以使用形如 a[7:4] 的方式取出 a 的第 7-4 位数据。
信号定义好之后,不仅决定了位宽还决定了方向。
可以有
wire [3:0] a,也可以有wire [0:3] a,在方向上有区分
需要注意的是,信号变量与 C 语言中的变量有所不同,不能像 C 语言一样随意赋值,一般需要按照组合逻辑的规则进行操作。
reg型
reg 型(register)是寄存器数据类型,具有存储功能。一般在 always 块内使用 reg 型变量,通过赋值语句来改变寄存器中的值。为了确定何时进行赋值,我们经常需要用到各种控制结构,包括 while、for、switch 等。
在always过程块中要求被赋值变量必须为reg型。reg 型变量不能使用 assign 赋值。而且,reg 型并不一定被综合成寄存器,它也可和 always 关键字配合,建模组合逻辑。
利用 reg 数据类型建模存储器
可以对 reg 型变量建立数组来对存储器建模,例如 reg [31:0] mem [0:1023];,其中前面的中括号内为位宽,后面的中括号内为存储器数量。mem[2] 就是访问 mem 中的第 3 个元素。
理解 Verilog HDL 的关键在于“站在硬件的角度”来看待程序的设计与运行。
数字字面量
Verilog 中的数字字面量可以按二进制(b 或 B)、八进制(o 或 O)、十六进制(h 或 H)、十进制(d 或 D)表示。
数字的完整表达为 <位宽>'<进制><值>,如 10'd100。省略位宽时采用默认位宽(与机器有关,一般为 32 位),省略进制时默认为十进制,值部分可以用下划线分开提高可读性,如 16'b1010_1011_1111_1010。
Verilog 中除了普通的数字以外,还有两个特殊的值:x 和 z。
-
x为不定值,当某一二进制位的值不能确定时出现,变量的默认初始值为x。 -
z为高阻态,代表没有连接到有效输入上。对于位宽大于1的数据类型,x与z均可只在部分位上出现。
integer 型
integer 数据类型一般为 32 位,与 C 语言中的 int 类似,默认为有符号数,在实验中主要用于 for 循环
parameter 型
parameter 类型用于在编译时确认值的常量,通过形如 parameter 标识符 = 表达式; 的语句进行定义,如:parameter width = 8;。在实例化模块时,可通过参数传递改变在被引用模块实例中已定义的参数(模块的实例化将在后面的章节进行介绍)。parameter 虽然看起来可变,但它属于常量,在编译时会有一个确定的值。
parameter 可以用于在模块实例化时指定数据位宽等参数,便于在结构相似、位宽不同的模块之间实现代码复用。
组合逻辑建模
assign 语句
assign 语句是连续赋值语句,是组合逻辑的建模利器,其作用是用一个信号来驱动另一个信号。如 assign a = b;,其中 a 为 wire 型(也可由位拼接得到,见运算符部分),b 是由数据和运算符组成的表达式。
assign 语句与 C 语言的赋值语句有所不同,这里“驱动”的含义类似于电路的连接,也就是说,a 的值时刻等于 b。这也解释了 assign a = a + 1; 这样的语句为什么是不合法的。由于这样的特性,assign 语句不能在 always 和 initial 块中使用。assign 意味着左侧的信号值始终等于右侧,因此assign w1=w1 | w1是错误的。
未被驱动的 wire 型变量可以理解为一段没有连接任何信号的导线,它和其他导线相连是没有意义的。
assign连接wire型数据,表示线的直接连接,因而时刻改变联想实际的电路
assign 语句经常与三目运算符配合使用建模组合逻辑。一般来说,assign 语句综合出来的电路是右侧表达式化简后所对应的逻辑门组合。
时序逻辑建模
always 块
always 块有如下两种用法:
- 若
always之后紧跟@(...),其中括号内是敏感条件列表,表示当括号中的条件满足时,将会执行always之后紧跟的语句或顺序语句块。这种用法主要用于建模时序逻辑。always的敏感条件列表中,条件使用变量名称表示,例如always @(a)表示当变量a发生变化时执行之后的语句;- 若
always之后紧跟@ *或@(*),则表示对其后紧跟的语句或语句块内所有信号的变化敏感。这种用法主要用于与reg型数据和阻塞赋值配合,建模组合逻辑。 - 若条件前加上
posedge关键字,如always @(posedge a),表示当a达到上升沿,即从0变为1时触发条件,下降沿不触发;加上negedge则是下降沿触发条件,上升沿不触发。
- 若
- 每个条件使用逗号
,或or隔开,只要有其中一个条件被触发,always之后的语句都会被执行。
- 若
always紧跟语句,则表示在该语句执行完毕之后立刻再次执行。这种用法主要配合后面提到的时间控制语句使用,来产生一些周期性的信号。
在always过程块中要求被赋值变量必须为reg型。
initial 块
initial 块后面紧跟的语句或顺序语句块在硬件仿真开始时就会运行,且仅会运行一次,一般用于对 reg 型变量的取值进行初始化。initial 块通常仅用于仿真,是不可综合的。
if-else语句
Verilog 中 if 语句的语法和 C 语言基本相同,也有 else if、else 这样的用法。
但是,if 语句只能出现在always中的顺序块中,其后的分支也只能是语句或顺序块。
if的硬件含义:MUX多路选择器
case 语句
case 语句同样只能出现在顺序块中,其中的分支也只能是语句或顺序块。
与 C 语言不同,case 语句在分支执行结束后不会落入下一个分支,而会自动退出。
由实际的硬件含义决定
1 | always @(posedge clk) begin |
需要指出的是,case 语句进行的是全等比较,也就是每一位都相等(包括 x 和 z)才认为相等。
for 语句
循环变量
integer 和 reg 类型的变量均可作为循环变量,使用 reg 类型变量作为循环变量时需要合理设置位宽,防止进入死循环状态。
此代码会造成
Isim崩溃,可以发现仿真进入死循环,不会输出finish!。这是因为循环变量
temp是位宽为 2的reg型变量,当循环计数到达3时,temp + 1溢出,计数将再次从0开始,如此重复,不会出现temp大于3的情况,循环将一直被执行。
2
3
4
5
6
7
initial begin
for (temp = 2'h0; temp <= 2'h3; temp = temp + 1) begin
$display("run the loop");
end
$display("finish!");
end
循环结束条件最好写为常数而不是变量。
for 语句对应实际线路
实际的电路中是没有循环功能的,for语句实现的循环功能的实质是批量实现硬件功能,用形式上的循环完成了硬件上的多硬件。
以下是一个 for 循环对应的线路示例:
1 | module test( |
对应线路:
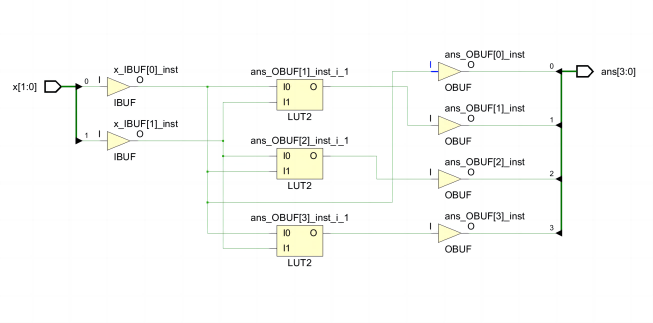
如上图所示,示例代码对应一个累加电路形成的组合电路,使用 3 个 LUT2 单元实现。
while 语句
Verilog 中 while 语句的语法和 C 语言基本相同。下面给出一个例子:对一个 8 位二进制数中值为 1 的位进行计数
1 | module count1s_while( |
在 Verilog 中所有的循环语句只能在 always 或 initial 块中使用,因此 for 语句和 while 语句不能直接出现在语句块外。
循环语句中即可用非阻塞赋值,也可用阻塞赋值,所以 for 语句和 while 语句既可以用于建模组合逻辑(非阻塞赋值),也可以用来建模时序逻辑(阻塞赋值)。
能否用来建立时序逻辑的标准为能否使用阻塞赋值
时间控制语句
时间控制语句通常出现在测试模块中,用来产生符合期望变化的测试信号
这个语句通过关键字 # 实现延时,格式为 #time,当延时语句出现在顺序块中时它后面的语句会在延时完毕后继续执行。举例如下:
1 | #3; // 延迟 3 个时间单位 |
Verilog语言特性
常用运算符
Verilog HDL 中有相当多的运算符都与 C 语言基本相同,如:
- 基本运算符:
+,-,*,/,%等 - 位运算符:
&,|,~,^,>>,<<等 - 逻辑运算符:
&&,||,!等 - 关系运算符:
>,<,>=,<=等 - 条件运算符:
? :
这些运算的运算规则与 C 语言相同,只是在操作数中出现了不定值 x 和高阻值 z 的话最终结果可能也是带 x 或 z 的。
另外 Verilog 中没有自增、自减运算符。下面主要介绍其他与 C 不同的部分:
-
逻辑右移运算符
>>与算术右移运算符>>>它们的区别主要在于前者在最高位补 0,而后者在最高位补符号位,但是需要声明为有符号数
$signed(a)>>>b才可以。 -
相等比较运算符
==与===和!=与!==-
==和!=可能由于不定值x和高阻值z的出现导致结果为不定值x -
而
===和!==的结果一定是确定的 0 或 1(x与z也参与比较)。
-
-
阻塞赋值
=和非阻塞赋值<=-
这两种赋值方式被称为过程赋值,通常出现在
initial和always块中,为**reg型变量**赋值。不同于assign语句,赋值仅会在一个时刻执行。 -
由于 Verilog 描述硬件的特性,Verilog程序内会有大量的并行,因而产生了这两种赋值方式。可以联想为寄存器形式的赋值。在描述时序逻辑时要使用非阻塞式赋值
<=。 -
这个是
b<=a的示意
-
-
位拼接运算符
{}- 这个运算符可以将几个信号的某些位拼接起来,例如
{a, b[3:0], w, 3'b101};; - 可以简化重复的表达式,如
{4{w}}等价于{w,w,w,w}; - 还可以嵌套,
{b, {3{a, b}}}等价于{b, {a, b, a, b, a, b}},也就等价于{b, a, b, a, b, a, b}。
- 这个运算符可以将几个信号的某些位拼接起来,例如
-
缩减运算符
- 运算符
&(与)、|(或)、^(异或)等作为单目运算符是对操作数的每一位汇总运算,如对于reg[31:0] B;中的B来说,&B代表将B的每一位与起来得到的结果。 - 对多位数据进行运算得到单位数据
- 运算符
有符号数和无符号数
对于真正想要使用有符号数,需要加上$signed(),如:c=$signed(a)>$signed(b)。如果一个有符号和另一个无符号做运算,则默认类型匹配为无符号数。
原理
Verilog 对于符号的处理有些特殊,分为最外层表达式符号的确定与向内传播两个过程。也就是说先确定下来最终结果有无符号,再向内传播进行类型转换,诸多诡异行为的罪魁祸首就是向内传播:只要子式有无符号式,则整体表现为无符号。
自决定:与外部无关,自身决定符号
上下文决定:表达式含有其他常量/变量,符号和位宽由**“上下文”**决定
- 这体现为一个递归问题,从内到位一次决定符号性质
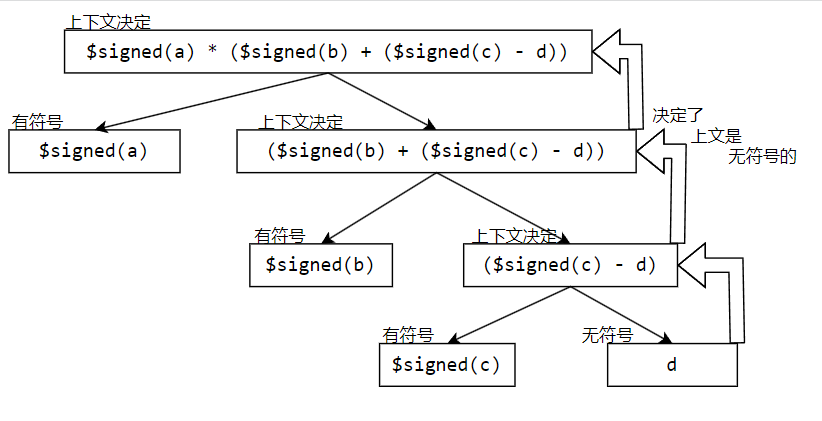
- 在Verilog中, 对于数字常量的直接表示(如0,1)会被识别为32-bit的有符号整数, 对于指定位宽和进制的会被作为无符号整数。如果希望对后者的形式也作为有符号数出现,可以$signed()或者在进制声明前加入"s", 改写为4’sb0
特殊情况
对于布尔表达式等,Verilog 语言规定关系表达式与等式表达式属于自确定与上下文决定的中间态,具体体现为结果是自确定的,但是它们的子表达式需要相互影响。
对于移位运算符,其右侧的操作数总是被视为无符号数,并且不会对运算结果的符号性产生任何影响。结果的符号由运算符左侧的操作数和表达式的其余部分共同决定。
对于三目运算符,其?前的布尔表达式是自决定的表达式,不会对最外层表达式的符号造成影响。:两边会互相影响。
如果实在担心使用 $signed() 会出现意想不到的 bug,那么最简单的方式就是避开它。比如符号拓展可以写成如下
1 | wire [1:0] unsignedValue = 2'b11; |
一道有意思的题:verilog-signed_verified-2
2
3
4
5
6
7
8
9
10
11
12
13
14
input clk,
input reset,
input [3:0] a,
input [3:0] b,
output [3:0] ans1,
output [3:0] ans2,
output [3:0] ans3
);
assign ans1 = (1'b1==1'b1) ? a>>>b : 0;
assign ans2 = (1'b1==1'b1) ? $signed(a)>>>b : 0;
assign ans3 = (1'b1==1'b1) ? $signed(a)>>>b : 4'b0;
endmoduleTestbench部分内容如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Initialize Inputs
clk = 0;
reset = 0;
a = 0;
b = 0;
// Wait 100 ns for global reset to finish
#100;
// Add stimulus here
a=3;
b=1;
#2;
a=-2;
b=1;
endT1. 在101ns和103ns时,ans1的值分别为( )。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
T2. 在101ns和103ns时,ans2的值分别为( )。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
T3. 在101ns和103ns时,ans3的值分别为( )。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
答案:ABA
解析:这道题三种情况表示了有符号数的表达式向内扩散。 >>> 运算符的意义是符号右移。
- ans1 的性质较好确定,整个表达式都是无符号的,所以最高位不会添加 1。
- ans2 与 ans3 的主要区别在于 : 后面是 0 还是 4’b0。
- 若是 0 则默认当作有符号数,则整个表达式被决定为有符号表达式。拓展时是符号拓展。
- 而 ans3 中有一个原子表达式 4’b0 是无符号的,这样整个表达式都决定为无符号表达式,对于有符号的需要强制类型转换。
宏定义的简单使用
在 Verilog HDL 语言中,为了和一般的语句相区别,编译预处理命令以符号` (反引号,backtick)开头。
宏定义的一般形式为:
1 |
注意,引用宏名时也必须在宏名前加上符号 `,以表明该名字是经过宏定义的名字。
编写testbench
Testbench(测试器)其本质是一个 module,用于测试已编写好的 module 的正确性,可以将其看作一个“驱动装置”。可以为其添加临时变量,组合逻辑等内容来辅助仿真。
1 | module alu_tb; |
- 标注有“Inputs”和“Outputs”注释的地方,是我们模块输入输出端口的转化,其中仿真模板将输入用
reg变量替代,便于我们直接对其值进行设置。 initial语句块是需要修改的部分,使用关键字“#”开头的延迟控制语句进行时间控制,将输入端口在不同的时间赋予我们期望的数据。请注意,该语句声明的是延迟时间,而不是整个仿真过程的时间戳。
模块实例化
模块实例化的目的是方便其他模块调用。
对电路元件模块实例化最常见的语法是:<模块名> <实例名>(端口信号映射);。
其中,端口信号映射方式也有两种:
- 位置映射:
<模块名> <实例名>(信号 1, 信号 2, ...);,其中信号 n 对应被实例化模块声明时排在第 n 位的端口。 - 名映射:
<模块名> <实例名>(.端口名 a(信号 1), .端口名 b(信号 2), ...);,其中信号 n 对应其前的端口名。
值得注意的是,在实例化元件时,wire 类型信号可以被连接至任意端口上,但 reg 类型的信号只能被连接至元件的输入端口上。在声明元件时,我们可以将任意端口声明为 wire 类型,但只能将输出端口声明为 reg 类型,否则会出现问题。
我们也可以悬空部分不需要连接的端口,下图的uut_0、uut_1、uut_2分别对应位置映射、名映射与悬空端口的实例。建议每一行只连接一个端口信号避免混乱。
1 | // Instance the Unit Under Test (UUT) |
编译预处理
define
编译预处理,可以类比 C 语言中的 #define 等语句。即用一个指定的标识符来代表一个字符串,一般形式为:
1 |
如:
1 |
它的作用是指定用标识符 signal 来代替 string 这个字符串,在编译预处理时,把程序中该命令以后所有的 signal 都替换成 string。
include
在编译的时候,需要对 include 命令进行"文件包含"预处理:将 File2.v 的全部内容复制插入到 include "File2.v" 命令出现的地方,即使 File2.v 被包含到 File1.v 中。在接着往下进行编译中,将"包含"以后的 File1.v 作为一个源文件单位进行编译。
注意:
-
可以将多个
include命令写在一行,这一行除include命令以外,只可以含有空格和单行注释。例如下面的写法是合法的:1
`include "fileB" `include "fileC" // including fileB and fileC
-
如果文件 1 包含文件 2,而文件 2 要用到文件 3 的内容,则可以在文件 1 用两个 ``include` 命令分别包含文件 2 和文件 3,而且文件 3 应出现在文件 2 之前。
-
不能有同名模块,因而在
include时要注意
timescale
timescale 命令用来说明跟在该命令后的模块的时间单位和时间精度。使用 timescale 命令可以在同一个设计里包含采用了不同的时间单位的模块。例如,一个设计中包含了两个模块,其中一个模块的时间延迟单位为纳秒 (ns),另一个模块的时间延迟单位为皮秒 (ps)。EDA 工具仍然可以对这个设计进行仿真测试。
timescale 命令的格式如下:
1 | `timescale [时间单位]/[时间精度] |
条件编译命令 ifdef, else, elsif, endif, ifndef
这些条件编译编译指令用于编译期间的源描述。
ifdef 编译器指令检查 text_macro_name 的定义,如果定义了 text_macro_name,那么 ifdef 指令后面的行被包含在内。如果未定义 text_macro_name 并且存在 else 指令,则编译 else 后的源描述。
ifndef 编译器指令检查 text_macro_name 的定义。如果未定义 text_macro_name,则包含 ifndef 指令后面的行。
如果定义了 text_macro_name 并且存在 else 指令,则编译 else 后的源描述。如果 elsif 指令存在(注意不是 else),编译器会检查 text_macro_name 的定义。如果定义存在,则包含 elsif 指令后面的行。
elseif 指令等同于编译器指令序列 else,ifdef ...endif。该指令不需要相应的 endif指令。该指令必须以 ifdef 或 ifndef 指令开头。
系统任务
Verilog 中还提供了很多系统任务,类似于 C 中的库函数,使用这些系统任务可以方便地进行测试。
在此仅对 $display, $monitor, $readmemh 进行介绍。
输出信息
格式:$display(p1, p2, ..., pn);
这个系统任务的作用是用来输出信息,即将参数 p2 到 pn 按参数 p1 给定的格式输出。用法和 C 语言中的 printf 类似。下面用一个例子简单介绍其用法。
例如:
1 | module disp; |
其输出结果为: a = 10,b = 20
其中 %d 表示以十进制的形式输出,\n 为换行符。
在此说明几种常用的输出格式:
| 输出格式 | 说明 |
|---|---|
| %h 或 %H | 以十六进制数的形式输出 |
| %d 或 %D | 以十进制数的形式输出 |
| %b 或 %B | 以二进制数的形式输出 |
| %c 或 %C | 以 ASCII 码字符的形式输出 |
| %s 或 %S | 以字符串的形式输出 |
监控变量
格式:
$monitor(p1, p2, ..., pn);$monitor;$monitoron;$monitoroff;
任务 $monitor 提供了监控和输出参数列表中的表达式或变量值的功能。其参数列表中输出控制格式字符串和输出列表的规则和 $display 中的一样。
当启动带有一个或多个参数的 $monitor 任务时,仿真器则建立一个处理机制,使得每当参数列表中变量或表达式的值发生变化时,整个参数列表中变量或表达式的值都将输出显示。
如果同一时刻,两个或多个参数的值发生变化,则在该时刻只输出显示一次。
$monitoron 和 $monitoroff 任务的作用是通过打开和关闭监控标志来控制监控任务 $monitor 的启动和停止,这样使得程序员可以很容易地控制 $monitor 何时发生。其中 $monitoroff 任务用于关闭监控标志,停止监控任务 $monitor , $monitoron 则用于打开监控标志,启动 $monitor 监控任务。
$monitor 与 $display 的不同处还在于 $monitor 往往在 initial 块中调用,只要不调用 $monitoroff, $monitor 便不间断地对所设定的信号进行监视。
读取文件到存储器
格式:
$readmemh("<数据文件名>", <存储器名>);$readmemh("<数据文件名>", <存储器名>, <起始地址>);$readmemh("<数据文件名>", <存储器名>, <起始地址>, <结束地址>);
功能: $readmemh 函数会根据绝对/相对路径找到需要访问的文件,按照 ASCII 的解码方式将文件字节流解码并读入容器。
文件中的内容必须是十六进制数字 0~f 或是不定值 x,高阻值 z(字母大小写均可),不需要前导 0x,不同的数用空格或换行隔开。
假设存储器名为arr,起始地址为s,结束地址为d,那么文件中用空格隔开的数字会依次读入到 arr[s],arr[s+1]... 到 arr[d]。假如数字的位数大于数组元素的位数,那么只有低位会被读入,剩下的高位会被忽略。
此系统任务用来从文件中读取数据到存储器中,类似于 C 语言中的 fread 函数。
例如:
1 | module im; |
仿真后即可将 code.txt 中的内容读入 im_reg 存储器中。
层次化事件队列
在 Verilog 的语法中,以 begin-end 为开头结尾的代码块被称作顺序块,也就是说从细节上理解-其中代码执行是按顺序进行的。但是实例中我们又称 always 块中的非阻塞赋值是“并发执行”的,从概念上似乎出现了矛盾。
其实,“并发执行”并不是运行规则,而是运行规则作用后的外在效果,真正的规则实际上是 Verilog 代码运行时的层次化事件队列。
层次化事件队列是硬件仿真(Simulation)时,用于规定“不同事件执行的优先级关系”。根据事件的优先级,Verilog 将其分为 4 个队列:队列间的优先级不同,从上到下优先级依次递减,只有当优先级高的队列中所有任务完成后,才会继续完成优先级较低的任务
- 动态事件队列:动态事件队列在队列内部执行顺序无硬性规定,但在同一个
begin-end语句块中的语句应当严格按照源代码中的顺序执行;且多个非阻塞赋值应当按照语句执行顺序进行- 阻塞赋值
- 计算非阻塞赋值语句右边的表达式(
RHS) - 连续赋值(如
assign) - 执行
display命令
- 停止运行的时间队列(#0)
- 非阻塞事件队列:更新非阻塞赋值语句 LHS(左边变量)的值。
- 监控事件队列(执行
monitor,strobe命令)
在
Verilog或System Verilog中,在一个always语句块中同时使用阻塞赋值和非阻塞赋值可能会引入不可预测的行为和硬件仿真问题。这种混合使用可能导致以下问题:
- 冲突和竞争条件:阻塞赋值和非阻塞赋值有不同的优先级和执行顺序。当它们同时存在时,可能会引发信号赋值的竞争条件,这可能会导致不确定的电路行为。这可能会使仿真结果与预期不符,或者在实际硬件中引发问题。
- 代码可读性差:混合使用阻塞和非阻塞赋值会增加代码的复杂性,降低可读性。这会使代码更难以理解和维护,因为开发人员需要考虑不同赋值方式之间的交互。
- 不确定的延迟:阻塞赋值通常会引入更多的延迟,因为它们会等待前一个赋值完成后才会执行下一个。非阻塞赋值则可以并行执行。因此,混合使用这两种方式可能导致不确定的延迟,使设计变得更加复杂。
为了避免这些问题,通常建议在一个
always语句块中只使用一种赋值方式,以确保代码的可预测性和可维护性。选择使用阻塞赋值还是非阻塞赋值取决于设计的需求和意图。通常情况下,非阻塞赋值更适合用于描述时钟边沿触发的行为,而阻塞赋值更适合用于组合逻辑。
default nettype
Verilog的默认缺省类型是 wire,如果我们不对某个变量显式声明类型或显式定义,而直接使用,该变量将会被默认地设为 wire 类型。
如果在使用该变量之后再对该变量显式声明,则变量的类型以之后显式声明的类型为准。
1 | module test(input wire[3:0] temp); |
在这个示例中,b 的值变成了 4'b1000。在语法检查或仿真时,可以看到编译器产生了如下警告:
WARNING:HDLCompiler:35 - “test.v” Line N: <b> is already implicitly declared earlier.
这一语法特性容易造成一个问题:如果我们在对模块进行连接的时候,忘记对于某一个变量进行定义,或将变量名打错,如将 alu 打成 aiu,则该变量将会默认被定义为 1 位宽的 wire 类型,造成意料之外的 bug。
这时有一种解决方法:使用 ``default_nettype`。
1 | module test(input temp); |
default_nettype 用于设置缺省类型,在代码文件的任意位置加入 default_nettype 宏,都可以使得该代码文件中所有变量的缺省类型改变。若代码中有两个以上的 default_nettype 宏,则将会以最后一条为准。
若需要取消缺省类型,即若不显式声明类型就会报错,则应该使用 ``default_nettype none`。未显式指定类型而报错。
函数
函数用关键词 function 声明,并用 endfunction 结束,不允许输出端口声明(包括输出和双向端口),但可以有多个输入端口。函数只返回一个值到函数被调用的位置,并且在函数中返回值与函数名同名。
函数的定义如下所示:
1 | function [range] function_id; |
在使用函数时有以下几点需要注意:
- 函数定义只能在模块中完成,不能出现在过程块中;
- 函数至少要有一个输入端口;不能包含输出端口和双向端口;
- 在函数结构中, 不能使用任何形式的时间控制语句 (
#、wait等) , 也不能使用disable中止语句; - 函数定义结构体中不能出现过程块语句(
always语句); - 函数内部可以调用函数,但不能调用任务。
一个简单的例子:
1 | module comb15 (A, B, CIN, S, COUT); |
在函数调用中,有下列几点需要注意:
- 函数调用可以在过程块中完成,也可以在
assign这样的连续赋值语句中出现。 - 函数调用语句不能单独作为一条语句出现,只能作为赋值语句的右端操作数。
可综合的Verilog代码
像 Verilog 这样的 HDL 语言,只有当编写的 Verilog 代码能被准确地综合成硬件,它才是有意义的。
不要用 initial 块、不要为寄存器赋初值
在真实的电路中没有初始化赋值。initial 块用于在仿真开始时对寄存器进行初始化、执行其他代码。在综合时,initial 块会被忽略,不起任何作用,且为 reg 指定的初始值也会被忽略。
如果你想在模块开始运行时,对寄存器进行一些初始化,请使用 reset 信号控制复位,并在 Testbench 开始的部分提供一个 reset 信号。例如,代码正确写法为:
1 | always @(posedge clk) begin |
Testbench 正确的写法:
1 | reg clk = 0; |
一个寄存器只能在一个 always 块中赋值一次
Verilog 综合时,寄存器通常会被综合为 D 触发器:
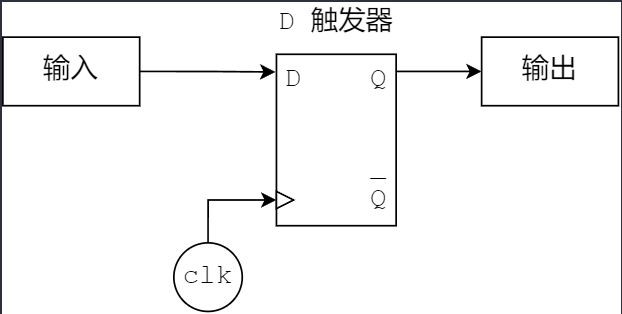
可以看到,D 触发器只有一个时钟输入、一个数据输入。因此,每个寄存器只能属于一个时钟域(“时钟域”指驱动触发器更新的时钟所表示的“范围”)。
除了注意时钟域的归属外,我们也需保证在每个时钟周期中,寄存器被至多赋值一次,不能重复赋值。
需要注意的是“赋值一次”的含义。如果使用 if / else / case 语句进行条件判断,在不同且互斥的情况下对同一个寄存器进行赋值,是完全合法的。虽然这里出现了两条对 d 进行赋值的语句,但这两条语句是“互斥”的,并不会对 d 重复赋值。上面的代码会被综合成如下的硬件(if的硬件含义是MUX多路选择器):
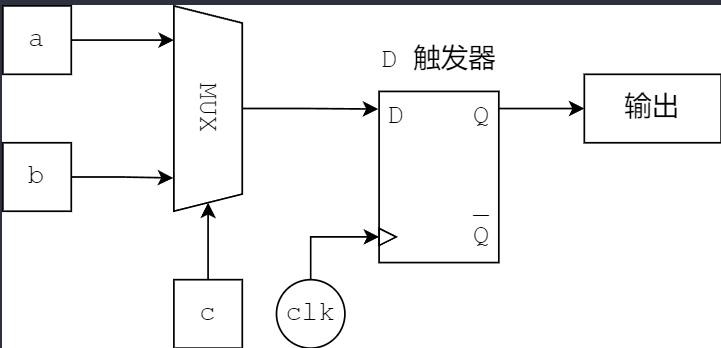
组合逻辑相关注意事项
我们一般会将代码分为“时序逻辑”和“组合逻辑”。时序逻辑使用 @(posedge clk) 来表达,而组合逻辑使用 @(*) 来表达。在编写组合逻辑时,依照以下准则编写代码,可避免综合后产生奇怪的故障。
- 在时序逻辑中,永远使用非阻塞赋值(
<=);在组合逻辑中,永远使用阻塞赋值(=); - 每个组合逻辑运算结果仅在一个
always @(*)中修改; - 在
always @(*)中,为每个运算结果赋初值,避免 latch 的产生。
一段示例代码如下。
1 | // 注意以下 count_n 并不是一个寄存器,而是由组合逻辑生成的运算结果;count 才是实际存放计数值的寄存器。 |
综合的其他要求
与仿真不同的常见综合化要求包括但不限于:
- 不使用
initial、fork、join、casex、casez、延时语句(例如#10)、系统任务(例如$display)等语句,具体可自行查阅学习。 - 用
always过程块描述组合逻辑时,应在敏感信号列表中列出所有的输入信号(或使用星号*)。 - 用
always过程块描述时序逻辑时,敏感信号只能为时钟信号。 - 所有的内部寄存器都应该能够被复位。
- 不能在一个以上的
always过程块中对同一个变量赋值。而对同一个赋值对象不能既使用阻塞式赋值,又使用非阻塞式赋值。 - 尽量避免出现锁存器(latch),具体避免方法有许多。例如,如果不打算把变量推导成锁存器,那么必须在
if语句或case语句的所有条件分支中都对变量明确地赋值。 - 避免混合使用上升沿和下降沿触发的触发器。
System verilog
logic
reg 变量好像暗指用时序逻辑的触发器搭建的硬件”寄存器”,然而实际上,reg 变量跟推断出的硬件没有任何关系.
System Verilog 使用更直观的 logic 关键字来描述通用的针对硬件的数据类型。我们将会看到你可以在过去 Verilog 中用 reg 型或是 wire 型的地方用 logic 型来代替。编译器可自动推断 logic 是 reg 还是 wire。
即 logic 是对 reg,wire 数据类型的改进,使得它除了作为一个变量之外,还可以被连续赋值、门单元和模块所驱动,显然,logic 是一个更合适的名字。
但以上的等同是在单驱动的情况下,因为 logic 只允许一个输入,wire 则无此限制。所以如果是多驱动的情况下,logic 和 wire 就不等同了。
新变量
bit——1 位两态整数。
byte——8 位两态整数,类似于C语言的 char。
shortint——16 位两态整数,类似于C语言的 short。
int——32 位两态整数,类似于C语言的 int。
longint——64 位两态整数,类似于C语言的 longlong。
always
在旧版本的 Verilog 中只有一个通用的 always 过程块,System Verilog 中追加了三个具有更明确目的专用 always 块:always_ff, always_comb, always_latch。
与原始的 always 块一样,这三个新的东西也是无限循环过程块,即每一个仿真周期都执行。
相比于 Verilog 简单的 always,System Verilog 对其进行了细化,看似多此一举其实是有合理性的,三个新的 always 块是专门针对可综合性 RTL 逻辑建模而定义的:
always_comb 用于可综合组合逻辑的建模。
always_ff 用于可综合时序逻辑的建模。
always_latch 用于锁存器的建模。
即:可以简单认为 always_comb 是 always @(\*) 的平替,always_ff @(posedge clk) 是 always @(posedge clk) 的平替。
改进的case语句
Verilog 的 case 语句允许在多个选项中选择一个逻辑分支。
在 System Verilog 中,我们当然可以继续使用 case 语句,但是这里也引入了两种新的case 语句:
unique case 和 priority case。
unique
该语句指定:
1.只有一个条件选项与条件表达式匹配。
2.必须有一个条件选项与条件表达式匹配。
这并不意味着我们不再需要 default 语句,相反,由于在复杂工程下我们很可能忘掉某些条件选项,所以 default 反而是必须的。这也同时为了防止锁存器的出现。
在这种语句下,每一个选项可以被并行执行判断,极大的提高了判断的效率。
priority
该语句指定:
-
至少有一个条件选项的值与条件表达式匹配。
-
如果有多个条件选项的值与条件表达式匹配,必须执行第一个匹配分支。
写法方面,由于这个和一般的 case 有所区别,所以给出样例:
1 | always_comb |
可以看出,常量取代了原来 case 中变量的位置,变量取代了 case 中常量的位置。 这个可以取代对一个变量进行 if,else if,else if,else 的判断过程。
全面C语言化
System Verilog 加入了很多十分类 C 的语句,主要如下:
break
类似于 C 语言,会立即终止循环的执行。
continue
类似于 C 语言,会跳转到循环的结尾然后执行循环控制。
return
类似于 C 语言,用来从非空函数返回或从空函数或任务中跳出。
typedef
基本格式为: typedef 已有类型 新类型
1 | typedef logic[31:0] word_t; |
struct
结构体 struct 可以描述一组相关的数据。
以译码器为例,按以前 Verilog 写法,可能需要这样写:
1 | logic [3:0] alufunc; |
在 System Verilog中,利用 struct 我们可以这样写:
1 | typedef struct packed { |
从上面例子我们需要注意,System Verilog 使用 '{} 符号包含数值列表,与{}拼接符作出区分。
第一种赋值方法需要我们按照结构体中元素定义顺序进行赋值,第二种则随意。
如果不用 typedef 进行包装 struct,在 System Verilog 中则认为生成了一个这样的结构体变量,而不是定义。
parameter
使用parameter用于适应不同的参数。
参数 parameter 的引进,可以让模块的设计变得更加灵活,复用性更高。
比如适用同一算法 int和long long 的加法器,使用 Verilog 需要写两个,但引用参数后只需要写一个模块。
使用方法样例:
1 | module ADD #( |
值得注意的是设置好参数后,如果在模块实例化时不设置参数,那么参数会使用默认值。
如上述理解,如果直接实例化不设置参数,那么 N 就会为 32(默认值)。
Mips
由于硬件方面的原因,CPU 所直接处理的都是一条条二进制机器码指令。而这些单纯的机器码是很难以阅读和理解的,汇编语言是一种助记符:用一些符号代表特定含义的机器码,用标签(Label)来替代地址。
MIPS 汇编的最大特点就是指令的结构比较单一,所有的指令都可以翻译成 32 位二进制的机器码,指令的组成也大都只有 R、I、J 这三类。
寄存器简介
对寄存器的访问速度远大于对存储器的访问速度,因而将少量常用的指令、数据保存到寄存器中。
MIPS通常有32个寄存器,其地址就是其编号(5位)。
在本次实验中的 CPU 是 32 位 CPU,一次能处理的最大位数即为 32 位,绝大部分寄存器也均是 1 字大小的(即 4 字节,也就是 32 位)。
在32位系统上,一个字为4字节,16位系统上为2字节
MIPS 中的 32 个通用寄存器按照序号命名为$0~$31,也可以按照功能命名。

| registers(也就是其地址) | Name(为了帮助记忆的名字) | 用途 |
|---|---|---|
$0 |
$zero |
常量0 |
$1 |
$at |
汇编器临时变量 |
$2-$3 |
$v0-$v1 |
函数返回值 |
$4-$7 |
$a0-$a3 |
函数参数 |
$8-$15 |
$t0-$t7 |
temp:临时变量,调用者保存 |
$16-$23 |
$s0-$s7 |
save:需要保存的变量,被调用者保存 |
$24-$25 |
$t8-$t9 |
temp:临时变量,调用者保存 |
$26-$27 |
$k0-$k1 |
操作系统临时变量 |
$28 |
$gp |
全局指针 |
$29 |
$sp |
栈指针 |
$30 |
$fp |
帧指针 |
$31 |
$ra |
函数返回地址 |
$0 始终为0,因为0经常在计算机程序中使用,提供了一个不同于立即数的常数
s寄存器和t寄存器的区别
-
对于 s 寄存器而言,被调用者需要保证寄存器中的值在调用前后不能发生改变
对应到实际操作中,如果你想要编写一个子函数,那么在这个子函数中使用的所有 s 寄存器,都必须要在函数的开头入栈,在函数的结尾出栈,以确保其值在这个函数被调用前后不会发生变化。
-
对于 t 寄存器而言则刚好相反,你编写的子函数中用到 t 寄存器的地方无需做任何保存,随意使用即可——因为维护 t 寄存器是上层函数的任务。
-
这也就是所谓的 :s 寄存器由被调用者维护,t 寄存器由调用者维护。
一个调用者(即父函数)并不能预知其将要调用的子函数(即被调用者)会使用到哪些 t 寄存器,但可能在调用时并不想失去自己正在使用的某个 t 寄存器中的数据。
在这种情况下,为了维持 t 寄存器中的数据,调用者有两种选择:一是将所有 t 寄存器中的数据移至 s 寄存器,函数调用结束之后再移回来;二是将自己希望保留的 t 寄存器压入栈中,函数调用结束之后再弹回来。
第一种方法看似简单,但实际上引入了很多潜在的问题,比如:s 寄存器用完了怎么办?怎么确保子函数一定不会破坏 s 寄存器中的数据?在自动生成汇编代码(如编译)的过程中,怎样确定哪些 s 寄存器是可以用来保存 t 寄存器中的数据的?
因此,采用第二种方法,是一个更优雅,也更规范的做法。在第二种方法里,不再需要去考虑寄存器之间如何倒腾,只需要借助 sp 指针,不停地用栈去存取自己需要的数据就可以了。这减少了程序员的心智负担,规范了函数调用的过程,也方便了编译器的实现。
总而言之,调用者维护 t 寄存器,被调用者维护 s 寄存器的意义,就在于让代码更易于模块化。在这种约定下,调用者不需要去考虑被调用者的具体细节,被调用者也不需要去考虑自己被调用的方式。这使得 mips 代码可以以函数为单位进行模块化开发。
汇编指令
指令,即是由处理器指令集架构定义的处理器的独立操作。这个操作一般是运算、存储、读取等。一个指令在 CPU 中真正的存在形式是高低电平,也可以理解为由01序列组成的机器码。
因为机器码人类难以阅读和理解,所以指令一般由汇编语言来表示。汇编指令只是一种助记符。一条指令的功能较为单一,一般不具有复杂的逻辑。
在 MIPS 汇编语言中,指令一般由一个指令名作为开头,后跟该指令的操作数,中间由空格或逗号隔开。指令的操作数的个数一般为 0-3 个,每一个指令都有其固定操作数个数。
一般来说,指令的格式如下:
指令名 操作数 1, 操作数 2, 操作数 3
不过,也有如下的指令格式,一般用于存取类指令:
指令名 操作数 1, 操作数 3(,操作数 2)
所谓操作数,即指令操作所作用的实体,可以是寄存器、立即数或标签,每个指令都有其固定的对操作数形式的要求。
标签用于使程序更简单清晰。标签用于表示一个地址,以供指令来引用。最终会由汇编器转换为立即数。
立即数,即在指令中设定好的常数,可以直接参与运算,一般长度为 16 位二进制。
标签一般用于表示一个数据存取的地址(类似于数组名)、或者一个程序跳转的地址(类似于函数名,或者 C 语言中
goto的跳转目标)。
每条指令的执行周期大多为 1 个 CPU 周期。因此机器码就是 CPU 最基本的一种操作,也是原子操作,不可被打断。
指令格式
32 位的机器码需要一定的格式才能被理解。一般来说,在 MIPS 指令集中,指令分为三种格式:R 型、I 型和 J 型。
区分 R 型指令,I 型指令与 J 型指令需要通过指令的机器码编码方式来确定。 R 型指令一般会有 rs, rt, rd 三种寄存器的编码; I 型指令会有 16 位的立即数; J 型指令会有 26 位的地址数。
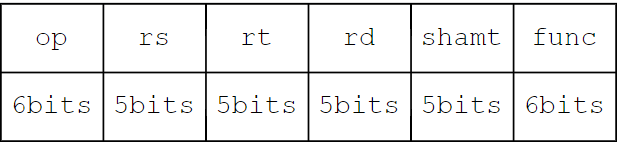
R 型指令
R 型指令的操作数最多,一般用于运算指令。例如 add、sub、sll 等。其格式如下(左侧为高位,右侧为低位):
I 型指令
I 型指令的特点是有 16 位的立即数(偏移也是一样的道理)。因此,I 型指令一般用于 addi、subi、ori 等与立即数相运算的指令(这里需要注意:在写汇编语言的时候,需要使用负号来标记负数,而不要和机器码一样认为首位的 1 就代表负数),或 beq、bgtz 等比较跳转指令,因为它们要让两个寄存器的值相比并让 PC 偏移 offset 这么多,刚好利用了全部的字段。还有存取指令,例如 sw、lw,它们在使用时需要对地址指定一个偏移值,也会用到立即数字段。

J 型指令
J 型指令很少,常见的为 j 和 jal。他们需要直接跳转至某个地址,而非利用当前的 PC 值加上偏移量计算出新的地址,因此需要的位数较多。
j 指令的地址空间共26位,可以表示64M(1024*1024)条指令,但是由于指令左移两位(相当于乘4),使得实际能达到的地址位256M
也可以看出,j指令能跳转达到的地址一定是4的倍数,是特定的语句的地址

jal跳转后,寄存器ra存储jal下一条指令的地址,方便跳回
jr register跳转到寄存器保存的地址
注意
地址相关
rs,rt,rd:在汇编程序和实际的机器指令中的相对位置- GPR :即 General Purpose Register (通用寄存器),其后的中括号内为寄存器编号。
GPR[rs]即可表示编号为rs的寄存器。 - memory:表示内存,当其后跟随中括号时,表示存储在以括号中数值为起始地址的 4 字节内存中的数据。
- 以
memory[Addr]为例,其表示以Addr为首地址的 4 字节内存中存储的数据。
- 以
读出和写入
sw,sb:从寄存器中读出写入存储器
lw,lb:从存储器读出写入寄存器
w:一个字,4个字节(一条指令为32位),地址偏移量必须为4的倍数
b:byte,地址偏移量可以任意
bit:1个0/1是1位,1字节byte=8bit
1字=4字节(32位机器),字是CPU一次处理指令的长度
伪指令(DIRECTIVES)
伪指令是用来指导汇编器如何处理程序的语句,有点类似于其他语言中的预处理命令。
在使用伪指令初始化数据时,伪指令存储的数据在内存中从.data声明的首地址开始,按照伪指令声明顺序紧密有序存储
伪指令不是指令,它并不会被编译为机器码,但他却能影响其他指令的汇编结果。
常用的伪指令有以下几个:
1 | .data #在此处声明了全局变量 |
-
.data:用于预先存储数据的伪指令的开始标志。格式:.data [address]
说明:
- 定义程序的数据段,初始地址为 address,若无 address 参数,初始地址为设置的默认地址。
- 需要用伪指令声明的程序变量需要紧跟着该指令。
-
.text:程序代码指令开始的标志。格式:.text [address]
说明:
- 定义程序的代码段,初始地址为 address,若无 address 参数,初始地址为设置的默认地址。
- 该指令后面就是程序代码。
- 在 MARS 中如果前面没有使用
.data伪指令,可以不使用.text直接编写程序代码,代码将放置在前面设置的代码段默认地址中;但如果前面使用了.data伪指令,务必在代码段开始前使用.text进行标注。
-
.space:申请若干个字节的未初始化的内存空间。格式:[name]: .space [n]
说明:
- 申请 n 个字节未初始化的内存空间,类似于其他语言中的数组声明。
- 这段数据的初始地址保存在标签
name中。 - name 的地址是由
.data段的初始地址加上前面所申请的数据大小计算得出的。由于前面申请的空间大小不定,有可能会出现后来申请的空间没有字对齐的情况,从而在使用sw,lw一类指令时出现错误,所以在申请空间时尽可能让 n 为 4 的倍数,防止在数据存取过程中出现问题。 - 在本例中,事先申请了 48 个字节也就是 12 个字的内存空间,用来保存我们之后计算出来的 12 个 Fibonacci 数,地址标签为 fibs。
-
.word:以字为单位存储数据。格式:[name]: .word [data1],[data2] ….
说明:
- 在内存数据段中以字为单位连续存储数据 data1, data2,… (也就是将 datax 写入对应的 1 个字的空间,注意 .word 和 .space 的区别)
- 这段数据的初始地址保存在标签 name 中。计算方式与上面相同。
-
.asciiz:以字节为单位存储字符串。格式:[name]: . asciiz “[content]”
说明:
- 以字节为单位存储字符串,末尾以 NULL 结尾。
- 每个字符(ascii)占8位
- 这个字符串在内存数据区的初始地址保存在标签 name 中。
- 注意
.asciiz与.ascii这两条伪指令的区别。.ascii伪指令不会在字符串之后添加0x00,.asciiz会添加0x00.asciiz由于是按字节存储,可能会导致之后分配的空间首地址无法字对齐的情况发生,请大家自行思考解决方法。
宏
宏分为两种,不带参数的宏和带参数的宏。
不带参数
不带参数的宏,定义的方式如下:
1 | macro_name |
可以定义这样一个宏:
1 | done |
此时,在需要程序停止运行的地方,使用 done 语句,就可以让程序在那里退出。这样就实现了代码复用。
带参数
带参数的宏,定义的方式如下:
1 | .macro macro_name(%parameter1, %parameter2, ...) |
和不带参数的宏不同的是,带参数的宏在 macro_name 后面有若干个用括号括起来的形式参数,每两个形式参数中间用逗号隔开,参数名前面有一个百分号。
可以定义这样一个宏:
1 | .macro getindex(%ans, %i, %j) |
其中%i代表行数,%j 代表列数,%ans 就是计算出来的结果 。使用 getindex($t2, $t0, $t1) 来调用这个宏,汇编器会用这段代码替换它,同时 %ans 被替换成 $t2,%i 被替换成 $t0,%j 被替换成 $t1,因此最终会被替换成
1 | sll $t2, $t0, 3 |
在矩阵乘法中,只需要替换调用宏的语句,问题就会被轻松解决,同时代码的复用性得到了提高,代码也更容易被人读懂。
常量定义
在汇编程序中,还有一种和C语言中 #define 类似的宏定义,一般用于常量的定义上,那就是 .eqv。用法如下:
1 | .eqv EQV_NAME string |
汇编器会把所有 EQV_NAME 的地方替换成 string,这可以用来定义一些常量。
可以用 .eqv 对数字编码进行定义,例如:
1 | .eqv TUBECHAR_0 0x7E |
使得代码更加清晰,并且避免了代码中出现各种意义不明的数字。
扩展指令
扩展指令的功能主要是简化程序。汇编器将一些常用功能封装为一条指令,或者改变现有指令的操作数的形式或个数,使其以新的形式出现。扩展指令是汇编器的功能,实际还是一条条的机器指令。
li
最常用到的一条扩展指令是li指令,它用来为某个寄存器赋值,比如 li $a0,100 就是将 100 赋给 $a0 寄存器。汇编器在翻译这条扩展指令时会根据需要,将它翻译成不同的基本指令或基本指令的组合。
- 第一条
li指令后面的立即数不多于 16 位,因此只被翻译成了一条addiu;$a0的地址是$4
- 第二条
li指令后面的立即数多于 16 位,因此被翻译成了lui+ori的组合。

la
另一条常用的扩展指令是 la 指令,是获取标签指向的地址,也就是使用地址来为寄存器赋值。标签本质上对应**一个 32 位地址。
- 比如
la $t0, fibs这条指令就是把 fibs 指向的地址存入$t0中。

系统调用
读取字符串的方式是以 $a0 存储器中存储的地址作为字符串的起始地址, 一直读取到 NULL, 也就是 0 为止.
考虑到字符结尾的 \0, 能够读取字符的最大数量应该是 $a1 寄存器所存储的值 - 1
-
字符串输出 代码:
1
2
3la $a0, addr
li $v0, 4
syscall说明:
- 首先把要输出的字符串在内存中的首地址赋给
$a0寄存器,然后汇编器就会根据$a0中的地址将字符串输出。 - 在内存中存储的字符串是以 NULL(‘\0’) 作为结束符,输出时遇到这个结束符就会停止。
- 首先把要输出的字符串在内存中的首地址赋给
-
整数输出
代码:
1
2li $v0, 1
syscall说明:这个系统调用的功能就是把
$a0寄存器中的数据以整数的形式输出。 -
结束程序
格式:
1
2li $v0, 10
syscall说明:结束程序
Mars
每个标签下的那块代码段一般都负责一部分功能,在设置断点调试程序时也大都是按照功能模块进行分块调试。
下面是一个求前12个Fibonacci数的一个程序:


假如我们对它进行初步调试,应该在哪几行设置断点比较合理呢?
答案:15,27,32
解析:这段代码的 .text 部分有 3 个标签:
loop,out。loop标签对应的代码段功能为计算前 12 个 Fibonacci 数,out标签对应的代码段功能为循环打印 Fibonacci 数列的每个数值。在
loop标签处(第15行)设置断点:
- 可以观察每次循环迭代时计算得到的 Fibonacci 数值,以及数组的变化情况。这有助于确保计算正确和查找潜在的计算错误。
在
- 可以查看计算完成后的最终结果,即前 12 个 Fibonacci 数列的值是否正确。这有助于确保计算和输出的正确性。
在
out标签处(第32行)设置断点:
- 可以观察循环打印 Fibonacci 数列的执行情况,逐个输出 Fibonacci 数值,并观察输出是否正确。这有助于验证输出循环的正确性和定位可能出现的问题。

汇编程序
循环
1 | .text |
在这段程序中,用到了大量的扩展指令

数组
数组的本质是存储器中连续的空间,相邻差4
1 | .data |
这里使用了 lw 和 sw 指令,对内存进行读写操作。lw 和 sw 要求地址对齐到字(即地址必须为 4 的倍数),否则会产生异常。由于字符串的长度不确定,并且打印字符串($v0 为 4)的 syscall 对 $a0 的值没有对齐要求,因此在一般情况下,会把字符串的声明放在最后。同学们可以尝试把 str 的声明挪到 array 声明的前面,如果运行程序时产生了异常,则可以尝试让 str 字符串增加或减少一些字符,直到内存指令不再出现异常。
二维数组
1 | .data |
栈
通常情况下,存储器仅给数据段.data和代码段.text分配了内存空间,没有给栈分配空间,所以会在数据段自己开辟一定的空间,存储一下局部、临时变量

使用规范
- 过程自身满足栈的结构:先进后出
- 过程调用子过程时需要满足栈的结构
- 子过程执行前后需要移动栈指针
$sp:分配和释放栈 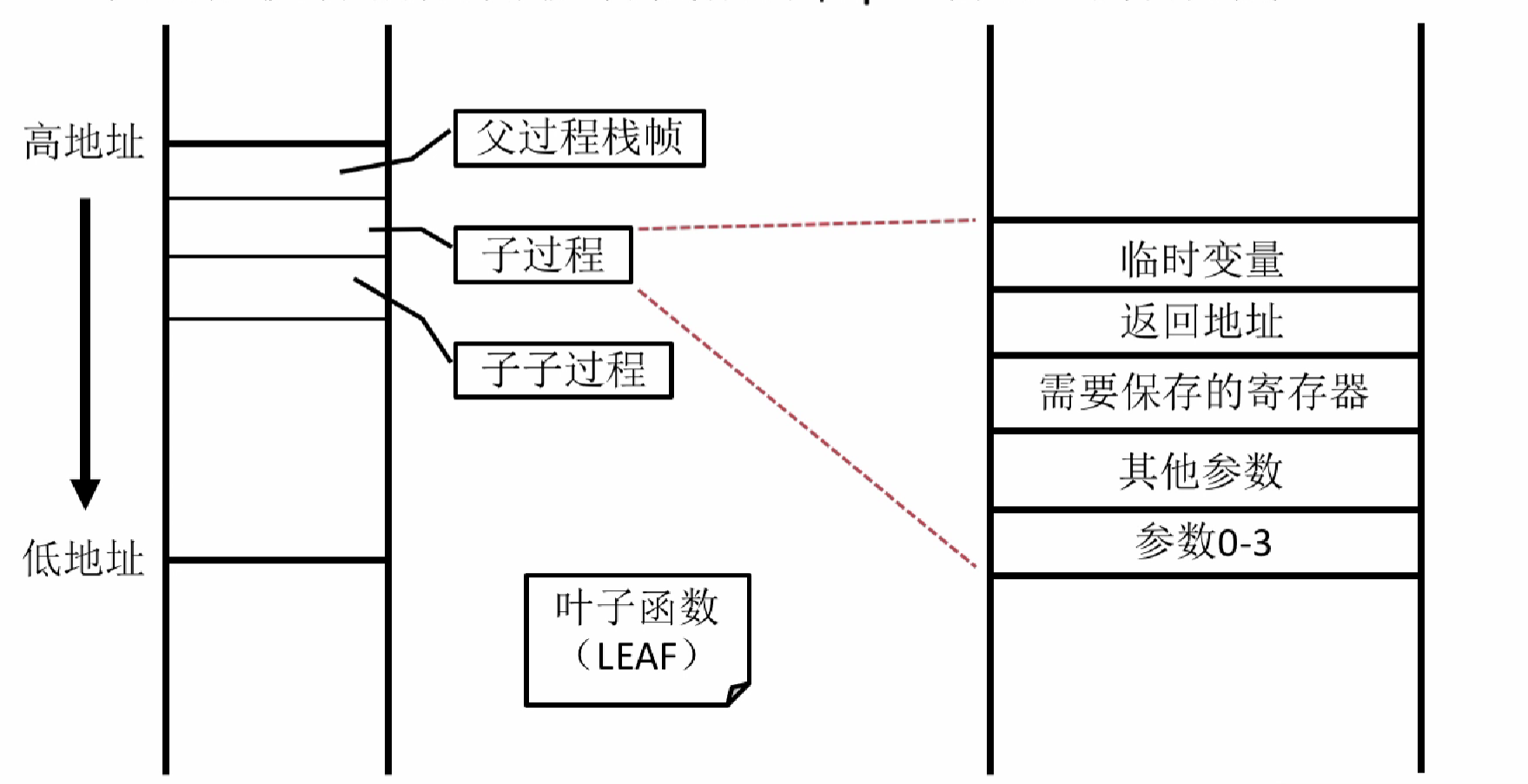
使用方法

维护一个栈的过程就是维护$sp指针的过程,默认一个数据存储16位的空间,即$sp=$sp-4,在这4个空间内存储数据。
函数调用
- 函数是一个代码块,可以由指定语句调用,并且在执行完毕后返回调用语句。
- 函数通过传参,可以实现代码的复用。
- 函数只能通过返回值等有限手段对函数外造成影响。
- 函数里依然可以嵌套调用函数。
复用代码
复用代码实现了程序的结构化:传入参数,有返回值
为了复用代码,就必须让一些特定寄存器作为“接收器”,对于不同的参数,都采用同一组寄存器来存储他们的值,也就是我们说的形参寄存器 $a0, $a1, $a2, $a3。同样的道理,对于返回值,也是需要指定特定的寄存器。
$a0, $a1, $a2, $a3 是一种程序员的约定,也可以用其他的寄存器或者存储入内存中。当需要传递的参数超过 4 个的时候,一般将多出的参数存入内存。在 MIPS 中,我们使用内存的一个主要方法就是利用栈,我们可以通过控制栈指针寄存器 $sp,完成对内存的访问。
不对外界造成影响
所以我们需要保证函数不会对外部造成影响,方法就是应用栈。
栈在这里的作用是保存和恢复函数使用的寄存器,函数应该计算返回值,但不应该产生其他的负面影响。
那么其实有两种使用栈的位置,第一种是在调用函数前,这种被称为调用者保存(在这里就是在 main 里面出入栈)。另一种是被调用者保存(在 sum 里出入栈)
实际使用更多的是在函数中管理栈:更好地函数化
嵌套函数调用
嵌套函数调用最重要的就是用栈保存跳转地址。
1 | .macro end |
递归函数调用
递归函数的本质就是一个在函数体内调用自身的嵌套函数。
1 |
|
汇编翻译版本为:
1 | # 程序结束 |
