
并行计算-CUDA
CUDA概述
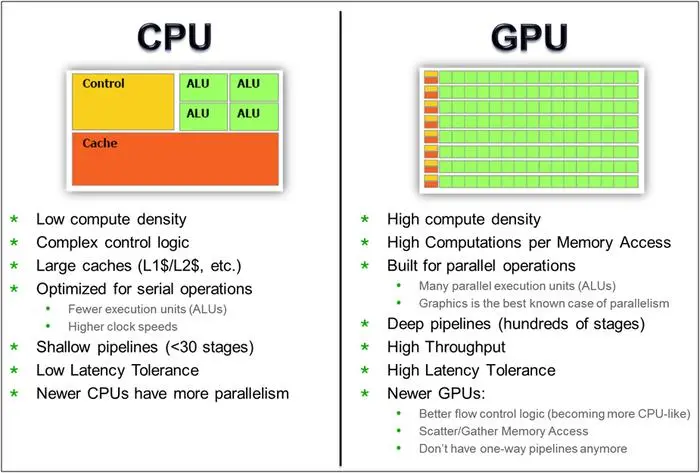
和CPU在设计理念上的不同:GPU有大量ALU,CPU大量面积留作Cache
软件上的名词
CUDA中线程也可以分成三个层次:线程、线程块和线程网络。
- 线程是CUDA中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block)是若干线程的分组,Block内一个块根据不同的GPU规格至多512个线程、或1024个线程,线程块可以是一维、二维或者三维的;
- 线程网络(Grid)是若干线程块的网格,Grid是一维和二维的。
- 线程组成线程块,线程块组成线程网络
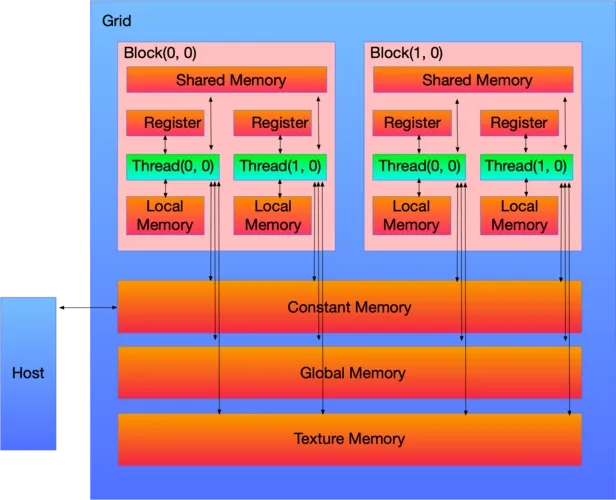
线程用ID索引,线程块内用局部ID标记threadID,配合blockDim和blockID可以计算出全局ID,用于SIMT(Single Instruction Multiple Thread单指令多线程)分配任务。
硬件上
GPU上有很多计算核心也就是Streaming Multiprocessor (SM),在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA里叫warp(一般32个线程或64线程)。
GPU在管理线程的时候是以线程块为单元调度到SM上执行。每个block中以warp作为一次执行的单位(真正的同时执行)。
- 一个 GPU 包含多个SM,而每个SM又包含多个 core 。SM支持并发执行多达几百的 thread 。
- 一个线程块只能调度到一个SM上运行,直到线程块运行完毕。但一个SM可以同时运行多个线程块(因为有多个core)。
一个线程块会被绑定到一个SM上,这个线程块只能在这个SM上运行,即使这个线程块内部可能有1024个线程,但这些线程组会被相应的调度器来进行调度,在逻辑层面上我们可以认为1024个线程同时执行,实际上在硬件上是一组线程同时执行,假如一个SM同时能执行64个线程,但一个block有1024个线程,那这1024个线程是分1024/64=16次执行,具体的执行受限于SM的实现。
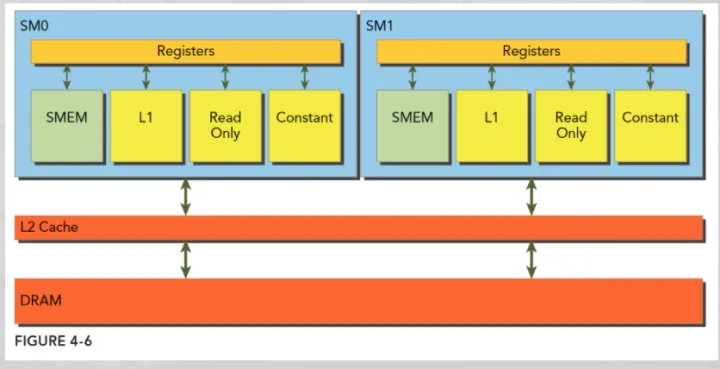
在cuda kernel中,跟SM对应的概念是block,每一个block会被调度到某个SM执行,一个SM可以执行多个block。
可伸缩的编程模型
CUDA 编程模型主要有三个关键抽象:层级的线程组,共享内存和栅同步(barrier synchronization)。
这些抽象提供了细粒度的数据并行和线程并行,可以以嵌套在粗粒的数据并行和任务并行中。它们鼓励将问题分解为子问题。每个子问题可以独立的在block threads中并行解决。同时每个子问题分成更细的部分,可以由块中的所有线程并行地合作解决。
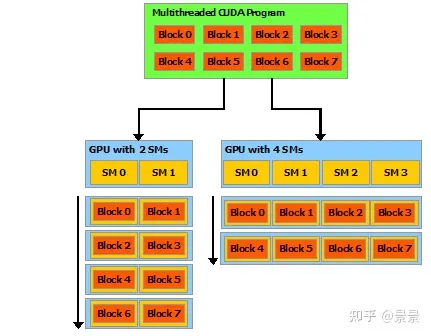
这种分解通过允许线程在解决每个子问题时进行协作来保留语言的表达性,同时支持自动可伸缩性。实际上,每个线程块都可以在GPU中任何可用的多处理器上调度,以任何顺序、并发或顺序,因此编译的CUDA程序可以在任意数量的多处理器上执行,如图所示,而且只有运行时系统需要知道物理多处理器的数量。
调用核函数
cuda 中的核函数与c++中的函数是类似的,cuda的核函数必须被限定词__global__修饰,核函数的返回类型必须是空类型,即void。
在核函数的调用格式上与普通C++的调用不同,调用核函数的函数名和()之间有一对三括号,里面有逗号隔开的两个数字。主机在调用一个核函数时,必须指明需要在设备中指派多少个线程,否则设备不知道怎么工作。三括号里面的数就是用来指明核函数中的线程数以及排列情况的。核函数中的线程常组织为若干线程块(thread block)。
三括号中的第一个数时线程块的个数,第二个数可以看作每个线程块中的线程数。一个核函数的全部线程块构成一个网格,而线程块的个数记为网格大小,每个线程块中含有同样数目的线程,该数目称为线程块大小。所以核函数中的总的线程就等与网格大小乘以线程块大小,即**<<<网格大小(线程块个数),线程块大小(线程个数) >>>**
1 |
|
cudaDeviceSynchronize();这条语句调用了CUDA运行时的API函数,去掉这个函数就打印不出字符了。因为cuda调用输出函数时,输出流是先放在缓存区的,而这个缓存区不会核会自动刷新,只有程序遇到某种同步操作时缓存区才会刷新。这个函数的作用就是同步主机与设备,所以能够促进缓存区刷新。
CUDA中的线程组织
核函数中允许指派很多线程,一个GPU往往有几千个计算核心,总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
使用网格数为2,线程块大小为4的计算核心,所以总的线程数就是2x4=8,所以核函数的调用将指派8个线程完成。
核函数中的代码的执行方式是“单指令-多线程”,即每一个线程都执行同一指令的内容。
线程索引的使用
一个核函数可以指派多个线程,而这些线程的组织结构是由**执行配置(<<<网格大小,线程块大小 >>>)**来决定的,这里的网格大小和线程块大小一般来说是一个结构体类型的变量,也可以是一个普通的整形变量。
一个核函数允许指派的线程数是巨大的,能够满足几乎所有应用程序的要求。但是一个核函数中虽然可以指派如此巨大数目的线程数(CUDA函数的弹性),但在执行时**能够同时活跃(不活跃的线程处于等待状态)**的线程数是由硬件(主要是CUDA核心数)和软件(核函数的函数体)决定的。
每个线程在核函数中都有一个唯一的身份标识。由于在三括号中使用了两个参数制定了线程的数目,所以线程的身份可以由两个参数确定。在程序内部,程序是知道执行配置参数grid_size和block_size的值的,这两个值分别保存在内建变量(built-in vari-able)中。
gridDim.x:该变量的数值等与执行配置中变量网格大小grid_size的数值。blockDim.x:该变量的数值等与执行配置中变量线程块大小block_size的数值。
在核函数中预定义了如下标识线程的内建变量:
blockIdx.x:该变量指定一个线程在一个网格中的线程块指标。其取值范围是从0到gridDim.x-1threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x-1
1 |
|
多维网络
gridDim、blockDim、blockIdx、threadIdx四个内建变量都使用了C++中的结构体或者类的成员变量的语法。
其中blockIdx和threadIdx是类型为uint3的变量。该类型是一个结构体,具有x,y,z三个成员变量。blockIdx只是三个成员中的一个,threadIdx也有xyz三个成员变量。结构体uint3在头文件vector_types.h中定义有。
同样的gridDim和blockDim是dim3类型的变量。也有xyz三个成员变量。

在前面三括号内的网格大小和线程块大小都是通过一维表示,可以通过dim3定义多维网格和线程块,通过C++的构造函数的方法实现:di3 grid_size(Gx.Gy,Gz);。如果第三个维度是1,可以省去不写。
1 | A kernel function must be called with an execution configuration: |
**多维的网格和线程块本质上还是一维的,就像多维数组本质上也是一维数组一样。**一个多维线程指标threadIdx.x、threadIdx.y、threadIdx.z对应的一维指标为。
tid = threadIdx.z * blockDim.x * blockDim.y +threadIdx.y * blockDim.x + threadIdx.x;这说明了,x维度是最内层的变化最快的,而z维度是最外层的变化最满的。
1 |
|
因为线程块的大小是2*4,所以在核函数中,blockDim.x的值为2,blokcDim.y值是4,threadIdx.x的取值是0到1,threadIdx.y的取值是0到3。
CUDA的程序框架
1 |
|
隐形的设备初始化
在cuda运行时API中,没有明显地初始化设备(GPU)的函数。在第一次调用一个和设备管理及版本管理及版本查询功能无关的运行时API函数时,设备将自动地初始化。
设备内存的分配与释放
在上述程序中,我们首先在主机中定义了三个数组并进行了初始化,通过cudaMalloc函数将它们指向了设备(GPU)中的内存,而不是主机的内存。该函数是一个cuda运行时API函数,所有cuda运行时API函数都以cuda开头。
使用cudaMalloc函数可以为不同类型的指针变量分配设备内存。为了区分主机和设备中的变量,使用d_作为所有设备变量的前缀,使用h_作为对应主机变量的前缀。
在c++中由
malloc()函数动态分配内存,在cuda中,设备内存的动态分配可由cudaMalloc()函数实现,函数原型如下:cudaError_t cudaMalloc(void **address,size_t size);该函数的功能是改变指针
d_x本身的值(将一个指针赋值给d_x),而不是改变d_x所指内存缓冲区中的变量值。需要将d_x的地址&d_x传给函数cudaMalloc()才能达到修改指针d_x本身的值的效果。其中第一个参数
address是待分配设备内存的指针。因为内存(地址)本身就是一个指针,所以待分配设备内存的指针就是指针的指针,即双重指针。第二个参数size是待分配内存的字节数。返回值是一个错误代码,如果调用成功,返回cudaSuccess,否则会返回一个代表错误的代号。
调用
cudaMalloc()函数时传入的第一个参数(void *)&d_x,其中d_x是一个double类型的指针,他的地址就是指针的指针,也就是双重指针,而使用(void * * )是一个强制类型转换操作。转换为void类型的双重指针。这种类型的转换可以不明确的写出来。所以cudaMalloc()函数的调用也可以简写为cudaMalloc(&d_x,M);
正如mallloc()函数分配的主机内存需要使用free()释放一样,用cudaMalloc()函数分配的设备内存需要用cudaFree()函数释放。该函数原型为cudaError_t cudaFree(void address);。这里参数address就是待释放的设备内存变量(不是双重指针),返回值是一个错误代号。
主机与设备之间数据的传递
在分配了设备内存之后,就可以将一些数据从主机传递到设备中去,使用cudaMemcpy()方法主机中的变量数据复制到设备中相应变量d_x和d_y所指向的缓冲区中。其方法的原型是:

- 第一个参数
dst是目标地址。 - 第二个参数
src是源地址。 - 第三个参数
count是复制数据的字节数。 - 第四个参数
kind是一个枚举类型的变量,标志数据传递方向。其中udaMemcpyHostToHost表示从主机复制到主机,udaMemcpyHostToHost表示从主机到设备。还有其他数据传递方向。 - 返回值是一个错误代号
该函数的作用是将一定字节的数据从源地址所值缓存区复制到目标地址所指缓存区。
核函数的要求
核函数是在GPU中运行的要求,CUDA对和函数的编写有一定的要求
- 返回值是void
- 限定符
- 函数名无特殊要求,支持C++中的重载,可以用同一个函数名表示具有不同参数列表的函数。
- 不支持可变数据的参数列表,即参数的个数必须确定。
- 可以向核函数传递非指针变量,其内容对每个线程可见。
- 除非使用统一内存编程机制,否则传给核函数的数组(指针)必须指向设备内存。
- 核函数不可成为一个类的成员,通常是用一个包装函数调用核函数,而将包装函数定义为类的成员。
- 在计算能力3.5之前,核函数之间不能互相调用。从计算能力3.5之后,引入 了动态并行机制,在核汉书内部可以调用其他核函数,甚至可以调用自己(递归)。
- 无论是从主机调用,还是从设备调用,核函数都是在设备中执行。调用核函数时必须指定执行配置,即三括号和它里面的参数。
自定义设备函数
核函数可以调用不带执行配置的自定义函数,这样的自定义函数称为设备函数。自定义设备函数是在设备中执行,并在设备中调用的。与之相比,核函数是在设备中执行,但是在主机端被调用的。
- 用
__gloabal__修饰的函数称为核函数,一般是由主机调用,在设备中执行。 - 用
__device__修饰的函数成为设备函数,只能被核函数或者其他设备函数调用,在设备中执行。 - 用
__host__修饰的函数就是主机端的普通C++函数,在主机中被调用,在主机中执行,修饰符可省。 - 不能同时用device和global 修饰一个函数,即不能将一个函数同时定义为设备函数和核函数。
- 也不能同时用host核global修饰一个函数。
