
计组-实验-P4
CPU设计
概述
本次我设计的verilog单周期CPU支持21条指令,采用多个模块进行设计。
所采用模块化设计为:
IFU:指令单元,接受指令地址PC来给出当前周期处理的指令GRF:寄存器模块,通过该模块统一进行32个寄存器的读写NPC:计算下一条指令的地址,接受jump,branch等指令来支持跳转操作ALU:进行运算操作,该ALU操作码为4为DM:内存组,通过内置的RAM实现Branch Control:分支跳转模块,判断是否该跳转ControlUnit:指令控制单元,通过接受op和func来发出指令,控制数据通路中的MUX
本次CPU的架构和P3作业中搭建的CPU架构相同,架构为:
支持指令
支持40条指令,为:
- R指令:
add,addu,sub,subu,and,or,xor,nor,sll,sllv,srl,srlv,sra,srav,slt,sltu - I指令:
addi,addiu,slti,sltiu,andi,ori,xori,lui,beq,bne,bgez,bgtz,blez,bltz,sw,lw,sh,sb,lh,lb - J指令:
j,jr,jal,jalr
数据通路模块定义
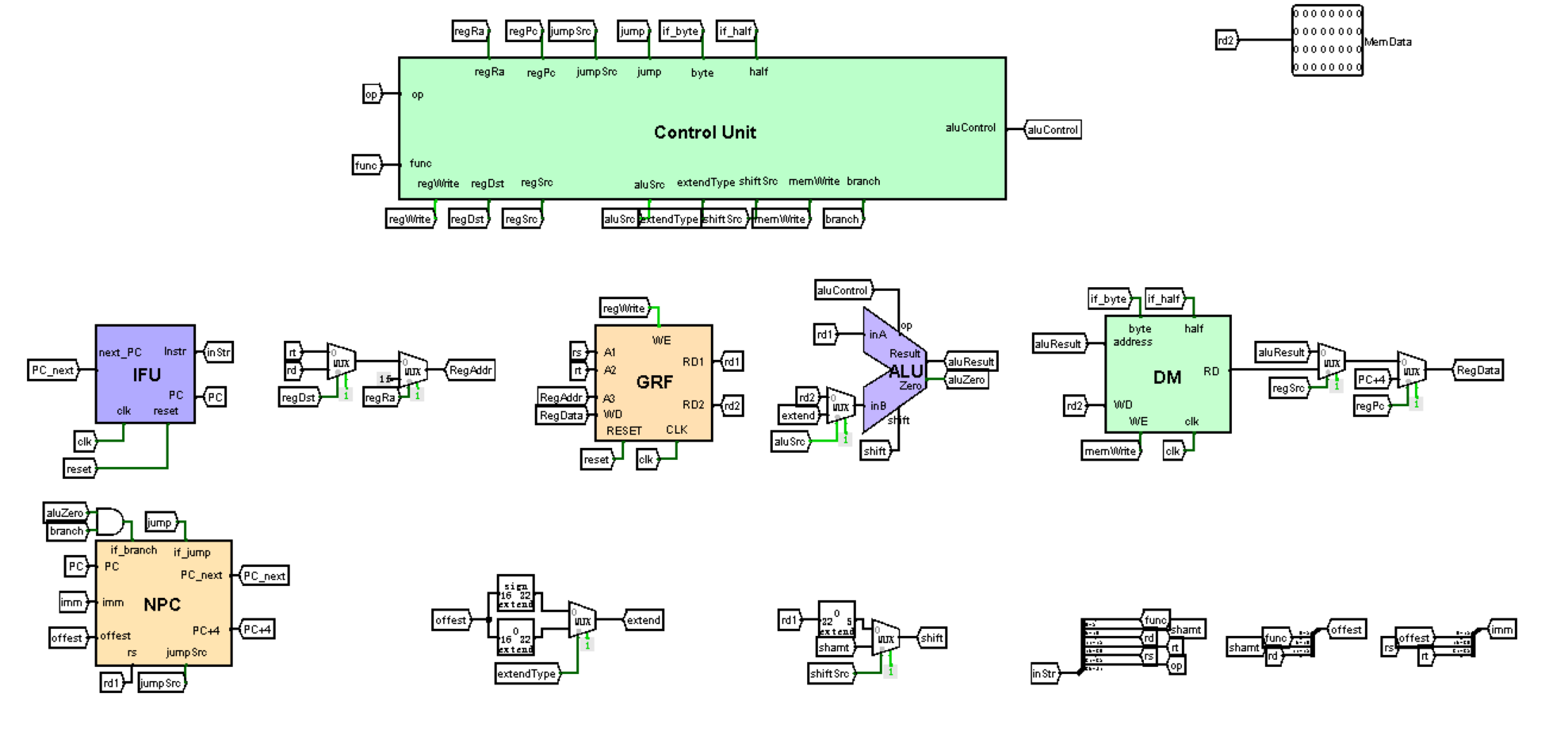
IFU:指令单元
该模块内部包含PC(程序计数器)和IM(指令存储器)。支持存储8192条指令。该部件集成了IM和PC,基本功能是取址-取指令。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
PC_next |
I | 32 | 下一条执行指令的地址 |
inStr |
O | 32 | 当前正在执行的指令 |
PC |
O | 32 | 当前正在执行指令的地址 |
功能定义
通过指令地址PC取得指令。
该组件支持同步复位,复位后输出的是地址为0x00003000处的指令。
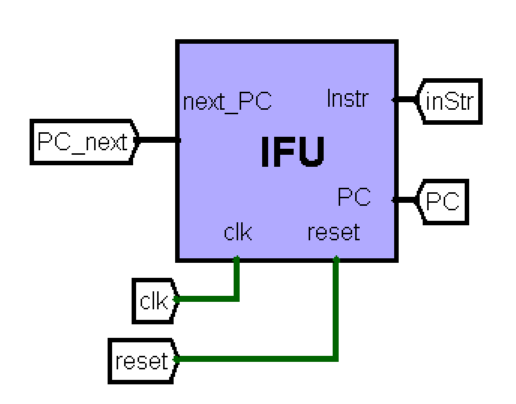
NPC:指令地址单元
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
PC |
I | 32 | 当前正在执行指令的地址 |
imm |
I | 26 | 对于J型指令时跳转的偏移量 |
offest |
I | 16 | 对于I型指令跳转时的偏移量 |
if_branch |
I | 1 | 是否进行I型指令的分支跳转 |
if_jump |
I | 1 | 是否进行J型指令的直接跳转 |
rs |
I | 32 | rs寄存器中的值 |
jumpSrc |
I | 1 | 跳转的地址选择是imm还是rs |
PC_next |
O | 32 | 输出计算后得到的下一个PC地址 |
PC+4 |
O | 32 | 输出当前输入PC值加4得到的PC值 |
功能定义
指令一共有三种情况:
- 不跳转,则
PC=PC+4 - 以
beq为代表的跳转,指令计算方式为PC和offest的计算,计算结果为PC_branch - J型指令跳转,指令计算有两种,通过
jumpSrc进行选择,计算结果为PC_jump- 以
j为代表的跳转,指令计算方式为立即数imm和PC的计算 - 以
jr为代表的跳转,指令计算方式为寄存器中储存的地址,即输入的rs寄存器中储存的值
- 以
同时,以为jal,jalr等指令会存储返回的地址,需要输出一个PC+4的地址
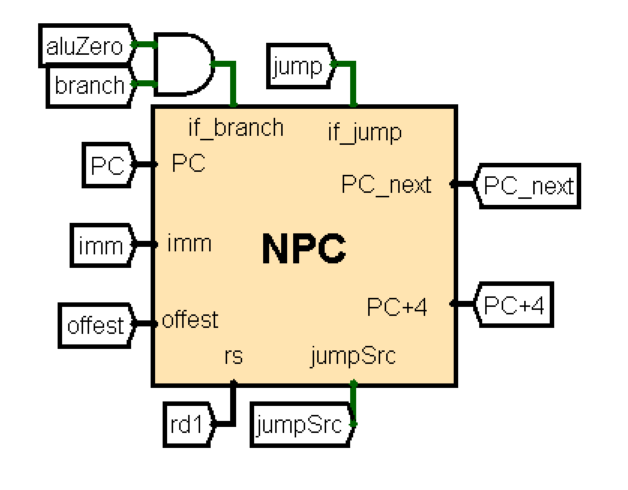
GRF:通用寄存器组
采用了P0课下实现的GRF。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
WE |
I | 1 | 写使能信号 |
A1 |
I | 5 | 读取编号1 |
A2 |
I | 5 | 读取编号2 |
A3 |
I | 5 | 写地址 |
WD |
I | 32 | 写数据 |
RD1 |
O | 32 | 输出读取编号1对应寄存器的值 |
RD2 |
O | 32 | 输出读取编号2对应寄存器的值 |
功能定义
实现了对寄存器堆的读写功能
ALU:计算单元

端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
inA |
I | 32 | 输入数据1 |
inB |
I | 32 | 输入数据2 |
op |
I | 4 | 计算类型 |
shift |
I | 5 | 偏移量 |
result |
I | 32 | 计算结果 |
zero |
O | 1 | 计算结果是否为0 |
功能定义
实现了如下操作加、建、与、或、异或、与或、左逻辑移位、右逻辑移位、右算数移位、大小判断操作。对应ALU操作码如下:
| 操作码 | 操作 |
|---|---|
| 0000 | A+B |
| 0001 | A-B |
| 0010 | A and B |
| 0011 | A or B |
| 0100 | A xor B |
| 0101 | ~ ( A OR B ) |
| 0110 | B << shift |
| 0111 | B >> shift |
| 1000 | B >>> shift |
| 1001 | B << 16 |
| 1010 | A < B |
| 1011 | A > B |
DM:内存
利用内置的RAM模拟了内存,可以对内存中的数据进行读写。支持对字、半字、字节的读写操作。
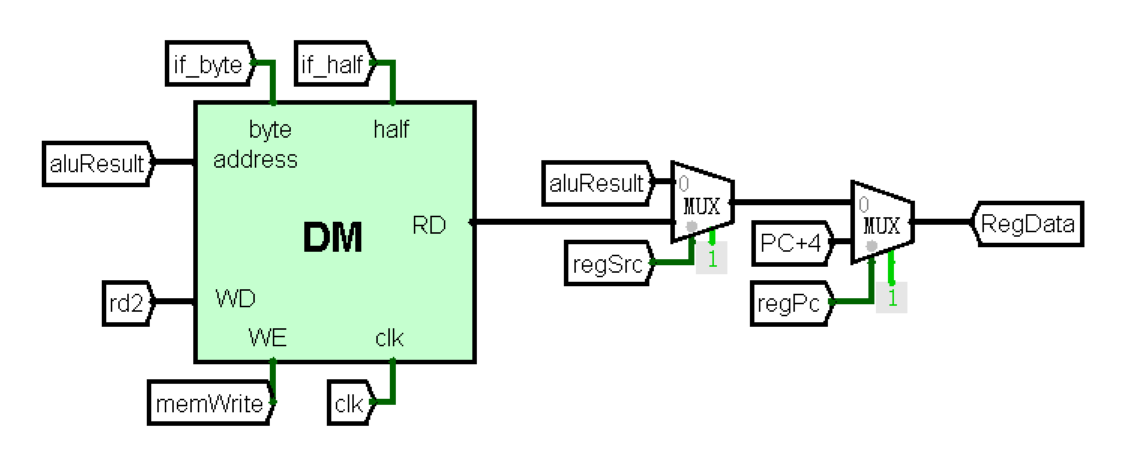
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
address |
I | 32 | 访问的内存地址 |
WD |
I | 32 | 写入内存的数据 |
WE |
I | 1 | 写使能 |
clk |
I | 1 | 时钟信号 |
byte |
I | 1 | 是否对字节进行读取 |
half |
I | 1 | 是否对半字进行读写 |
RD |
O | 32 | 读出内存的数据 |
功能定义
使用logisim内置的RAM模拟了内存,支持对字、半字、字节的读写操作。
对于读取:
- RAM为按字索引,故将输入的地址右移两位,得到对应在RAM中的数据,进行读写
- 按字读取,则此时
if_half和if_byte均为低电平,直接输出结果 - 按字节读取,此时
if_byte为高电平,操作逻辑为:- 取输入地址低两位,向左偏移3位得到对应的数据偏移量
shift。即如果低两位为01,代表读写8-15为的数据,需要左移三位。 - 对于读,将从RAM中读出的数据右移
shift位,再截取低8位,得到结果并输出 - 对于写,按照位运算的逻辑,将该地址在RAM中以存储的值
dm和输入数据中对应位的数据进行操作,再存入RAM中。能够实现依赖于RAM的阻塞赋值特性
- 取输入地址低两位,向左偏移3位得到对应的数据偏移量
- 按半字读取,此时
if_half为高电平,实现逻辑与按字节读取类似
Branch Control:分支控制
专门用来处理beq,bne,blez等指令,判断是否要进行分支跳转
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 具体的信号类型 |
rt |
I | 5 | rt的地址 |
if_zero |
I | 1 | rs和rt是否相等 |
data |
I | 32 | 具体数据,对应于和0比较的情况 |
if_branch |
O | 32 | 是否进行跳转 |
功能定义
对于分支,有以下这么几种情况:
beq和bne,通过读取GRF得到的rd1和rd2的数值大小关系进行比较- 和0比较的分支
bgez和bltz的op字段相同,靠rt字段进行区分- 在该模块中直接进行数值比较,需要注意的是应该为有符号数
Control Unit:控制单元
个人认为是CPU最关键的部分,依靠指令的op和func部分生成控制逻辑,控制电路中的MUX单元,实现具体的运算。
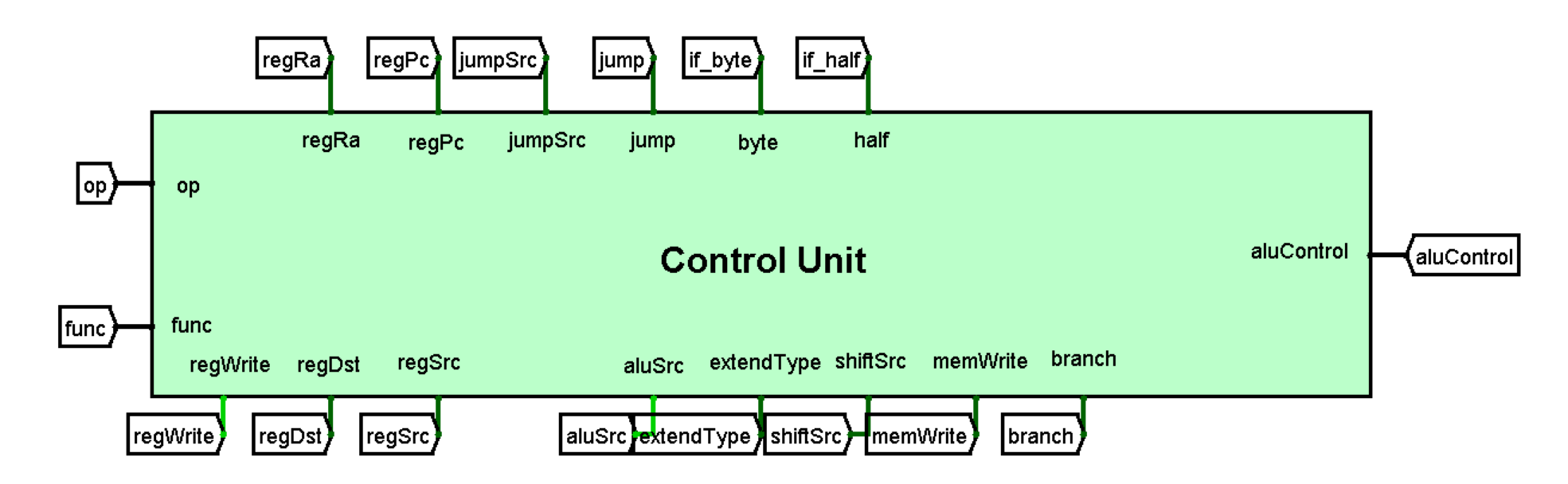
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 指令中的op段 |
func |
I | 6 | 指令中的func段 |
regWrite |
O | 1 | GRF写使能信号 |
regDst |
O | 1 | GRF的写入地址是rt还是rd |
regSrc |
O | 1 | GRF的写入数据来源是ALU还是内存 |
regRa |
O | 1 | GRF的写入地址是regSrc还是31 |
aluSrc |
O | 1 | ALU的输入数据2来自rt还是指令中的offest字段 |
extendType |
O | 1 | 对指令中offest字段extand的方式是sign还是zero |
shiftSrc |
O | 1 | ALU的shift输入来自rs还是指令中的shamt字段 |
memWrite |
O | 1 | DM的写使能信号 |
branch |
O | 1 | NPC的if_branch信号 |
jump |
O | 1 | NPC的if_jump信号 |
jumpSrc |
O | 1 | NPC的jumpSrc输入来自指令中的imm字段还是rs |
aluControl |
O | 4 | ALU的操作码 |
功能定义
根据指令的op字段和func字段,生成CPU的控制信号。
具体逻辑不表,给出对应的信号表:
| 0-1 | enable | rt-rd | regDst-31 | alu-mem | regSrc-PC+4 | rt-imm/off | sign-zero | rs-shamt | enable | enable | imm-rs | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| op | regWrite | regDst | regRa | regSrc | regPc | aluSrc | extendType | shiftSrc | memWrite | jump | jumpSrc | aluControl | alu | func | |
| add | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | + | 0000 | 100000 |
| addu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | + | 0000 | 100001 |
| sub | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | - | 0001 | 100010 |
| subu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | - | 0001 | 100011 |
| and | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | and | 0010 | 100100 |
| or | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | or | 0011 | 100101 |
| xor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | xor | 0100 | 100110 |
| nor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | nor | 0101 | 100111 |
| sll | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | 0 | x | << | 0110 | 000000 |
| sllv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | << | 0110 | 000100 |
| srl | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | 0 | x | >> | 0111 | 000010 |
| sra | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | 0 | x | >>> | 1000 | 000011 |
| srlv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | >> | 0111 | 000110 |
| srav | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | >>> | 1000 | 000111 |
| slt | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | < | 1010 | 101010 |
| sltu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | < | 1010 | |
| addi | 001000 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | + | 0000 | |
| addiu | 001001 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | + | 0000 | |
| slti | 001010 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | < | 1010 | |
| sltiu | 001011 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | < | 1010 | |
| andi | 001100 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | and | 0010 | |
| ori | 001101 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | x | or | 0011 | |
| xori | 001110 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | x | xor | 0100 | |
| lui | 001111 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | <-16 | 1001 | 101011 |
| beq | 000100 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | - | 0001 | |
| bgez | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | |
| bgtz | 000111 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | |
| blez | 000110 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | |
| bltz | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | |
| bne | 000101 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | - | 0001 | |
| j | 000010 | 0 | x | 0 | x | 0 | x | x | x | 0 | 1 | 0 | x | x | 001000 |
| jr | 000000 | 0 | x | 0 | x | 0 | x | x | x | 0 | 1 | 1 | x | x | |
| jal | 000011 | 1 | 1 | 1 | 0 | 1 | x | x | x | 0 | 1 | 0 | x | x | 001001 |
| jalr | 000000 | 1 | 1 | 0 | x | 1 | x | x | x | 0 | 1 | 1 | x | x | |
| sw | 101011 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | 0 | x | + | 0000 | |
| sh | 101001 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | 0 | x | + | 0000 | |
| sb | 101000 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | 0 | x | + | 0000 | |
| lw | 100011 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x | + | 0000 | |
| lh | 100001 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x | + | 0000 | |
| lb | 100000 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x | + | 0000 |
内部构成
使用了三个子模块:contorl1、control2、JumpControl。其中,各模块功能为:
-
control1:负责根据op字段生成和func无关的信号control1和control2之间通信的aluOp的含义:aluOp 含义 000 依赖 funct001 A + B 010 A - B 011 A or B 100 B << 16 -
control2:负责根据op和func字段生成其他信号,包括aluControl、shiftSrc -
JumpControl:负责生成和jump相关指令的控制信号,包括regRa、regPc、jumpSrc、jump
CPU测试
对于测试的认识
对于测试,我的一个思考就是在不考虑中断之前,大数据、边界值其实没有很大的意义,最多需要考虑位宽究竟设置对了没有——因为对于verilog这样的硬件描述语言来讲,溢出、数据错误往往都是来自于位宽没有对准、位宽错误,数据的范围就是位宽的范围。基于这样的认识,测试所需要的事其实就是两件:数据有没有放对寄存器、内存,数据的位宽对不对。
对于放对寄存器,这个很容易测,将数据在每个寄存器都放一遍,能放对就是得到了正确的结果。而去对于我所设计的CPU,不同质量的区别在于控制信号——都有着一样的数据通路,那么放对位置其实不用测很多次,R指令、I指令都各测一条实际上就可以达到测试效果。
对于位宽对不对的问题,只需要测试fff+fff这种大位宽、有进位数据即可,达到了测试位宽+正确性的效果。
测试方式
通过python程序将MIPS汇编程序(test.asm)编译并运行,形成16进制机器码(code.txt)和标准输出(mips_out.txt)。然后命令行运行ise,得到工程文件的输出(verilog_out.txt).然后我们对两个输出文件进行比较,得出比较结果。若出现不同,还会输出错误日志文件(log_i.txt)
借鉴了学长的博客
1 | import os |
思考题
-
阅读下面给出的 DM 的输入示例中(示例 DM 容量为 4KB,即 32bit × 1024字),根据你的理解回答,这个 addr 信号又是从哪里来的?地址信号 addr 位数为什么是 [11:2] 而不是 [9:0] ?

- addr信号的来源是ALU的计算结果输出端口,将计算结果计算后作为DM的地址
- 因为输入信号为按字节索引的地址,而DM的存储方式为按字索引,关系是除4,故可以直接从第3位开始;且地址长度位宽是10。
-
思考上述两种控制器设计的译码方式,给出代码示例,并尝试对比各方式的优劣。
-
第一种方式对于添加单个指令比较方便,可以直接添加,(个人认为对于上机更合适)。
但是在要添加控制信号时,这种方式较不方便,需要在每个指令中加入新的控制信号的具体取址
-
第二种控制信号对于添加控制信号时比较方便,似乎也是更为主流的方式。
缺点在于,对于默认信号就是1,对于为0、x的信号默认不添加
-
-
在相应的部件中,复位信号的设计都是同步复位,这与 P3 中的设计要求不同。请对比同步复位与异步复位这两种方式的 reset 信号与 clk 信号优先级的关系。
同步复位:clk的信号优先级高于clk
异步复位:两种信号的优先级相同
-
C 语言是一种弱类型程序设计语言。C 语言中不对计算结果溢出进行处理,这意味着 C 语言要求程序员必须很清楚计算结果是否会导致溢出。因此,如果仅仅支持 C 语言,MIPS 指令的所有计算指令均可以忽略溢出。 请说明为什么在忽略溢出的前提下,addi 与 addiu 是等价的,add 与 addu 是等价的。提示:阅读《MIPS32® Architecture For Programmers Volume II: The MIPS32® Instruction Set》中相关指令的 Operation 部分。
英文指令集中,对于ADD的解释是:ADDU performs the same arithmetic operation but does not trap on overflow,add和addu区别仅在于是否有溢出检测。在忽略溢出的条件下,两者都是计算-存入
GRF[rt],是等价的。
