
计组-实验-P6
CPU设计
概述
本次我设计的verilog流水线CPU支持50条指令。
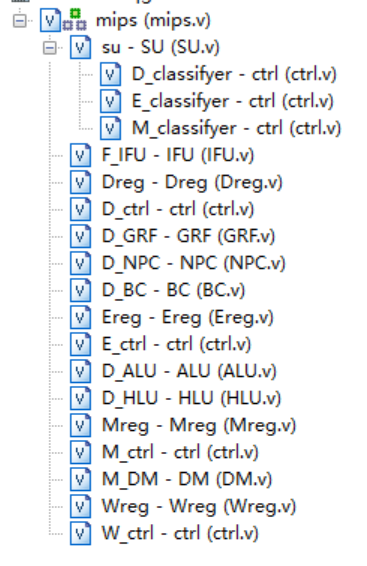
采用多个模块进行设计。
所采用模块化设计为:
IFU:指令单元,接受指令地址PC来给出当前周期处理的指令GRF:寄存器模块,通过该模块统一进行32个寄存器的读写NPC:计算下一条指令的地址,接受jump,branch等指令来支持跳转操作ALU:进行运算操作,该ALU操作码为4为DM:内存组,通过内置的RAM实现Branch Control:分支跳转模块,判断是否该跳转Stall Unit:阻塞单元,判断是否进行阻塞ControlUnit:指令控制单元,通过接受op和func来发出指令,控制数据通路中的MUX
支持指令
支持50条指令,基本支持了中文指令集文档上除了系统调用、异常外的所有指令。为:
- R指令:
add,addu,sub,subu,and,or,xor,nor,sll,sllv,srl,srlv,sra,srav,slt,sltu - I指令:
addi,addiu,slti,sltiu,andi,ori,xori,lui,beq,bne,bgez,bgtz,blez,bltz - J指令:
j,jr,jal,jalr - 存取存储器指令:
sw,lw,sh,sb,lh,lb,lhu,lbu - 乘除槽相关指令:
mfhi,mflo,mthi,mtlo,mult,multu,div,divu
数据通路模块定义
IFU:指令单元
该模块在外置IM后丧失了原本的作用,目前的作用是进行PC指令的复位,作为PC和PCnext指令的中转站。负责接受PCnext,向外输出当前正在执行的指令在IM中的存储地址PC。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
PCnext |
I | 32 | 下一条执行指令的地址 |
PC |
O | 32 | 当前正在执行指令的地址 |
功能定义
通过指令地址PC取得指令。
该组件支持同步复位,复位后输出的是地址为0x00003000处的指令。
NPC:指令地址单元
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
D_PC |
I | 32 | D级当前正在执行的指令 |
F_PC |
I | 32 | F级当前执行的指令 |
imm |
I | 26 | 对于J型指令时跳转的偏移量 |
offest |
I | 16 | 对于I型指令跳转时的偏移量 |
if_branch |
I | 1 | 是否进行I型指令的分支跳转 |
if_jump |
I | 1 | 是否进行J型指令的直接跳转 |
rs |
I | 32 | rs寄存器中的值 |
jumpSrc |
I | 1 | 跳转的地址选择是imm还是rs |
PC_next |
O | 32 | 输出计算后得到的下一个PC地址 |
功能定义
指令一共有三种情况:
- 不跳转,则
PCnext=F_PC+4 - 以
beq为代表的跳转,指令计算方式为PC和offest的计算,计算结果为PC_branch - J型指令跳转,指令计算有两种,通过
jumpSrc进行选择,计算结果为PC_jump- 以
j为代表的跳转,指令计算方式为立即数imm和PC的计算 - 以
jr为代表的跳转,指令计算方式为寄存器中储存的地址,即输入的rs寄存器中储存的值
- 以
由于延迟槽的引入,和跳转相关的指令都是在D_PC的基础上做运算,而正常情况下的PCnext则是F_PC+4,这是不一样的运算逻辑。
GRF:通用寄存器组
GRF为内置在CPU中的寄存器,也是在本CPU中最主要的数据存储单元。设有了两输出一输入端口。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
WE |
I | 1 | 写使能信号 |
A1 |
I | 5 | 读取编号1 |
A2 |
I | 5 | 读取编号2 |
A3 |
I | 5 | 写地址 |
WD |
I | 32 | 写数据 |
RD1 |
O | 32 | 输出读取编号1对应寄存器的值 |
RD2 |
O | 32 | 输出读取编号2对应寄存器的值 |
功能定义
实现了对寄存器堆的读写功能
ALU:计算单元
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
inA |
I | 32 | 输入数据1 |
inB |
I | 32 | 输入数据2 |
op |
I | 4 | 计算类型 |
shift |
I | 5 | 偏移量 |
result |
I | 32 | 计算结果 |
zero |
O | 1 | 计算结果是否为0 |
功能定义
实现了如下操作加、建、与、或、异或、与或、左逻辑移位、右逻辑移位、右算数移位、大小判断操作。对应ALU操作码如下:
| 操作码 | 操作 |
|---|---|
| 0000 | A+B |
| 0001 | A-B |
| 0010 | A and B |
| 0011 | A or B |
| 0100 | A xor B |
| 0101 | ~ ( A OR B ) |
| 0110 | B << shift |
| 0111 | B >> shift |
| 1000 | B >>> shift |
| 1001 | B << 16 |
| 1010 | A < B(有符号比较) |
| 1011 | A < B(无符号比较) |
HLU:乘除槽
对于乘除槽的引入,使得耗费较长时间的乘除运算可以单独进行,提高CPU流水的性能。
乘除槽中自带有LO和HI寄存器。在真实世界的CPU中,乘法操作需要5个时钟周期,除法操作需要10个时钟周期。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 32 | 时钟信号 |
reset |
I | 1 | 同步复位信号 |
inA |
I | 32 | 输入数据1 |
inB |
I | 32 | 输入数据2 |
dst |
I | 1 | 目标是LO还是HI |
write |
I | 1 | 对目标寄存器的写使能信号 |
hluType |
I | 2 | 运算的种类 |
unSigned |
I | 1 | 是否进行无符号运算 |
busy |
O | 1 | 乘除槽是否忙碌 |
result |
O | 32 | 目标寄存器存储的数据 |
功能定义
实现了乘除操作,同时使用状态机模拟了真实乘除操作的耗时。
可以读写LO、HI寄存器。
| 操作码 | 操作 |
|---|---|
| 00 | 无操作 |
| 01 | 乘法 |
| 10 | 除法 |
DM:内存
在内存外置后,DM的单元改变为对从内存中读出、写入的原始数据进行处理,使其符合运算规范。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
memData |
I | 32 | 原始的从内存中读出的原始数据 |
address |
I | 32 | 访问内存的地址 |
memIn |
I | 32 | 原始的欲写入内存的数据 |
WE |
I | 1 | 写使能 |
if_byte |
I | 1 | 是否按字进行读取 |
if_hlaf |
I | 1 | 是否按半字进行读取 |
load_extend |
I | 1 | 读取时是否进行符号扩展 |
memDataRead |
O | 32 | 处理后的读出内存的数据 |
memToWrite |
O | 32 | 处理后的写入内存的数据 |
byteen |
O | 4 | 对每个字的写使能信号 |
功能定义
对于数据的处理:由于引入了按字节使能的信号,所以需要对数据进行相应的移位操作来匹配字节。
- 写入:原始的数据,如0x00000012,如果想要写入3($0)的位置,则需要将数据左移16位进行匹配
- 读出:同样对按字、半字访问进行了相应的移位,同时按照
load_extend进行了相应的符号扩展 - 生成了按字节的写使能信号:对课程组的妥协,我觉得是愚蠢的操作
Branch Control:分支控制
专门用来处理beq,bne,bgez,bgtz,blez,bltz等指令,判断是否要进行分支跳转
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 具体的信号类型 |
rt |
I | 5 | rt的地址 |
rd1 |
I | 32 | 数据输入1 |
rd2 |
I | 32 | 数据输入2 |
if_branch |
O | 32 | 是否进行跳转 |
功能定义
对于分支,有以下这么几种情况:
beq和bne,通过读取GRF得到的rd1和rd2的数值大小关系进行比较- 和0比较的分支
bgez和bltz的op字段相同,靠rt字段进行区分- 在该模块中直接进行数值比较,需要注意的是应该为有符号数
Stall Unit:阻塞控制单元
通过接受CPU中的D级、E级、M级三级的指令,判断Tuse和Tnew,计算是否要进行阻塞。如果不阻塞,则进行无脑转发,以提高CPU的运行效率,减少考可能的阻塞(无脑阻塞理论参考了qsgg的博客))
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
D_inStr |
I | 32 | D级正在执行的指令 |
E_inStr |
I | 32 | E级正在执行的指令 |
M_inStr |
I | 32 | M级正在执行的指令 |
hl_busy |
I | 1 | 乘除槽是否进行操作 |
stall |
O | 1 | 在当前CPU的运行情况下,是否进行阻塞 |
功能定义
结合流水线各级的指令情况,判断此时是否能够进行转发,否则进行阻塞流水线。
核心的判断逻辑为:
- ,则进行阻塞
- 当前乘除槽正在进行乘除运算或开始执行,且F级为乘除槽相关指令,则进行阻塞
对于阻塞:
- D级流水寄存器写使能无效
- E级流水线寄存器清空
- 其余流水线寄存器正常执行
Control Unit:控制单元
个人认为是CPU最关键的部分,依靠指令的op和func部分生成控制逻辑,控制电路中的MUX单元,实现具体的运算。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 指令中的op段 |
func |
I | 6 | 指令中的func段 |
regWrite |
O | 1 | GRF写使能信号 |
regDst |
O | 1 | GRF的写入地址是rt还是rd |
regSrc |
O | 1 | GRF的写入数据来源是ALU还是内存 |
regRa |
O | 1 | GRF的写入地址是regSrc还是31 |
aluSrc |
O | 1 | ALU的输入数据2来自rt还是指令中的offest字段 |
extendType |
O | 1 | 对指令中offest字段extand的方式是sign还是zero |
shiftSrc |
O | 1 | ALU的shift输入来自rs还是指令中的shamt字段 |
memWrite |
O | 1 | DM的写使能信号 |
jump |
O | 1 | NPC的if_jump信号 |
jumpSrc |
O | 1 | NPC的jumpSrc输入来自指令中的imm字段还是rs |
aluControl |
O | 4 | ALU的操作码 |
if_byte |
O | 1 | 对内存的读取是否按字 |
if_half |
O | 1 | 对内存的读取是否按半字 |
load_extend |
O | 1 | 对内存读取结果是否进行符号扩展 |
| 乘除槽相关 | |||
resultSrc |
O | 1 | D级结果的来源是ALU还是HLU |
hluDst |
O | 1 | HLU操作的对象是LO还是HI |
hluWrite |
O | 1 | 对HLU的写使能 |
hluUnSigned |
O | 1 | 对HLU的操作是否为无符号操作 |
hluControl |
O | 2 | HLU的操作码 |
| 指令翻译相关 | |||
rs |
O | 5 | inStr的rs字段 |
rt |
O | 5 | inStr的rt字段 |
rd |
O | 5 | inStr的rd字段 |
dst |
O | 5 | 当前执行指令的目的寄存器是哪 |
| 指令分类相关 | |||
calr |
O | 1 | 是否为寄存器相关计算 |
cali |
O | 1 | 是否为立即数相关计算 |
store |
O | 1 | 是否为写入内存 |
load |
O | 1 | 是否为读出内存 |
jump_imm |
O | 1 | 是否按立即数跳转 |
jump_reg |
O | 1 | 是否按寄存器跳转 |
branch_r |
O | 1 | 是否按寄存器分支 |
branch_i |
O | 1 | 是否按立即数分支 |
shift_reg |
O | 1 | 是否按寄存器移位 |
shift_shamt |
O | 1 | 是否按shanmt字段移位 |
cal_hl |
O | 1 | 是否为乘除槽计算 |
read_read |
O | 1 | 是否为读出乘除槽 |
write_hl |
O | 1 | 是否为写入乘除槽 |
功能定义
根据指令的op字段和func字段,生成CPU的控制信号。
具体逻辑不表,给出对应的信号表:
| 0-1 | enable | rt-rd | regDst-31 | alu-mem | regSrc-PC+4 | rt-imm/off | sign-zero | rs-shamt | enable | sign-zero | enable | enable | enable | imm-rs | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| op | regWrite | regDst | regRa | regSrc | regPc | aluSrc | extendType | shiftSrc | memWrite | load_extend | if_half | if_byte | jump | jumpSrc | aluControl | alu | func | |
| add | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | + | 0000 | 100000 |
| addu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | + | 0000 | 100001 |
| sub | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | - | 0001 | 100010 |
| subu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | - | 0001 | 100011 |
| and | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | and | 0010 | 100100 |
| or | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | or | 0011 | 100101 |
| xor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | xor | 0100 | 100110 |
| nor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | nor | 0101 | 100111 |
| sll | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | << | 0110 | 000000 |
| sllv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | << | 0110 | 000100 |
| srl | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | >> | 0111 | 000010 |
| sra | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | >>> | 1000 | 000011 |
| srlv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | >> | 0111 | 000110 |
| srav | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | >>> | 1000 | 000111 |
| slt | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | < | 1010 | 101010 |
| sltu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | < | 1010 | |
| addi | 001000 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | + | 0000 | |
| addiu | 001001 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | + | 0000 | |
| slti | 001010 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | < | 1010 | |
| sltiu | 001011 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | < | 1010 | |
| andi | 001100 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | and | 0010 | |
| ori | 001101 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | x | x | x | 0 | x | or | 0011 | |
| xori | 001110 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | x | x | x | 0 | x | xor | 0100 | |
| lui | 001111 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | x | x | x | 0 | x | <-16 | 1001 | 101011 |
| beq | 000100 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | - | 0001 | |
| bgez | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |
| bgtz | 000111 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |
| blez | 000110 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |
| bltz | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |
| bne | 000101 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | x | x | x | 0 | x | - | 0001 | |
| j | 000010 | 0 | x | 0 | x | 0 | x | x | x | 0 | x | x | x | 1 | 0 | x | x | 001000 |
| jr | 000000 | 0 | x | 0 | x | 0 | x | x | x | 0 | x | x | x | 1 | 1 | x | x | |
| jal | 000011 | 1 | 1 | 1 | 0 | 1 | x | x | x | 0 | x | x | x | 1 | 0 | x | x | 001001 |
| jalr | 000000 | 1 | 1 | 0 | x | 1 | x | x | x | 0 | x | x | x | 1 | 1 | x | x | |
| sw | 101011 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | x | 0 | 0 | 0 | x | + | 0000 | |
| sh | 101001 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | x | 1 | 0 | 0 | x | + | 0000 | |
| sb | 101000 | 0 | x | x | x | 0 | 1 | 0 | 0 | 1 | x | 0 | 1 | 0 | x | + | 0000 | |
| lw | 100011 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | + | 0000 | |
| lh | 100001 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | x | + | 0000 | |
| lb | 100000 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | x | + | 0000 | |
| lhu | 100100 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | x | + | 0000 | |
| lbu | 100101 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | x | + | 0000 |
流水寄存器
共有Dreg、Ereg、Mreg、Wreg四个流水寄存器,存储了当前流水阶段执行所需的全部数据,输入输出有差别但大体类似,核心思想相同,不再赘述。
Dreg、Ereg支持阻塞功能,Dreg作为延迟槽还支持清空延迟槽功能。
CPU测试
对于测试的认识
对于测试,我的一个思考就是在不考虑中断之前,大数据、边界值其实没有很大的意义,最多需要考虑位宽究竟设置对了没有——因为对于verilog这样的硬件描述语言来讲,溢出、数据错误往往都是来自于位宽没有对准、位宽错误,数据的范围就是位宽的范围。基于这样的认识,测试所需要的事其实就是两件:数据有没有放对寄存器、内存,数据的位宽对不对。
对于放对寄存器,这个很容易测,将数据在每个寄存器都放一遍,能放对就是得到了正确的结果。而去对于我所设计的CPU,不同质量的区别在于控制信号——都有着一样的数据通路,那么放对位置其实不用测很多次,R指令、I指令都各测一条实际上就可以达到测试效果。
对于位宽对不对的问题,只需要测试fff+fff这种大位宽、有进位数据即可,达到了测试位宽+正确性的效果。
测试方式
按照我对测试的理解,手动生成测试数据,在迭代开发钟工作量其实并不大。
使用python程序进行一键运行,并使用标准库difflib进行可视化比较
- 通过python程序将MIPS汇编程序
test.asm编译并运行,形成16进制机器码code.txt和标准输出mips_out.txt。 - 使用命令行运行ise,得到工程文件的输出
verilog_out.txt。然后我们对两个输出文件进行比较,得出比较结果。 - 通过标准库
difflib运行得到可视化的输出比较保护视力
1 | import os |
思考题
-
为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
乘法需要5个时钟周期。除法需要6个时钟周期,过于花费时间。将乘除功能外置可以在进行乘除时执行其他指令,提高流水线CPU的性能,提高CPU的并行度。
-
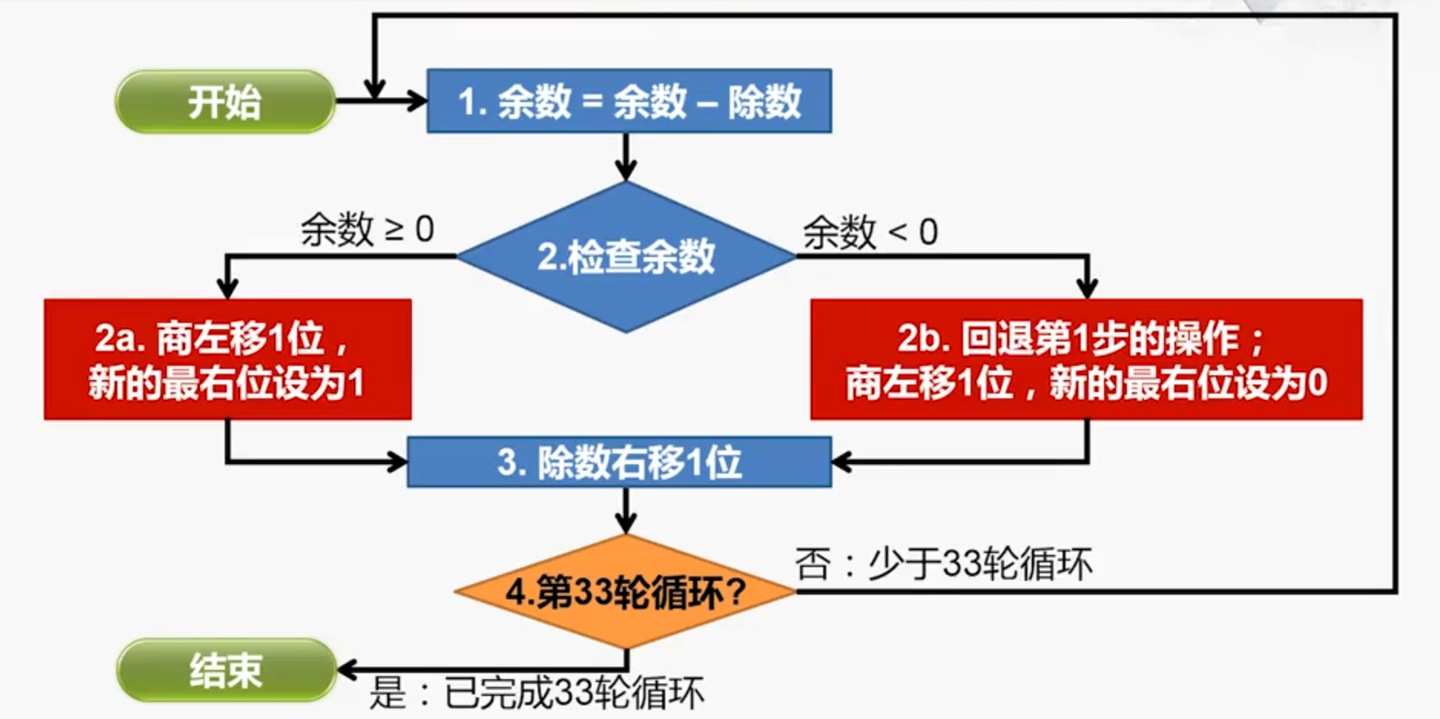
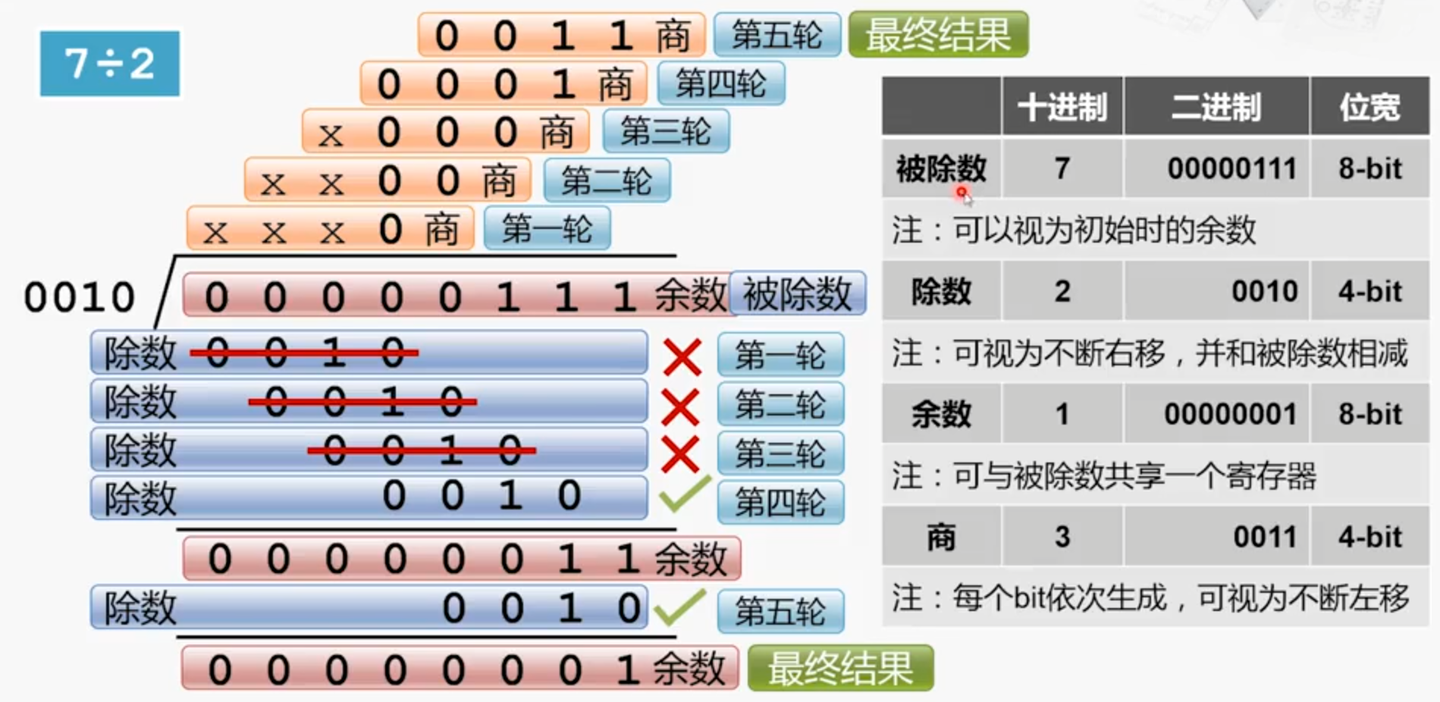
真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
为位运算和补码运算的组合,具体的实现逻辑为:
以下乘法器代码来自知乎:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
module mul_booth_signed(
input wire [`size - 1 : 0] mul1,mul2,
input clk,
input wire [2:0] clk_cnt,//运算节拍,相当于状态机了,8位的话每次运算有4个拍
output wire [2*`size - 1 : 0] res
);
//由于传值默认就是补码,所以只需要再计算“负补码”即可
wire [`size - 1 : 0] bmul1,bmul2;
assign bmul1 = (~mul1 + 1'b1) ;
assign bmul2 = (~mul2 + 1'b1) ;//其实乘数2的负补码也没用到。
//其实可以把状态机的开始和结束状态都写出来,我懒得写了,同学们可以尝试一下啊~
parameter zeroone = 3'b00,
twothree = 3'b001,
fourfive = 3'b010,
sixseven = 3'b011;
//y(i-1),y(i),y(i+1)三个数的判断寄存器,由于有多种情况,也可以看成状态机(也可以改写成状态机形式,大家自己试试吧)
reg [2:0] temp;
//部分积
reg [2*`size-1 : 0] A;
//每个节拍下把相应位置的数据传给temp寄存器
always @ (posedge clk) begin
case(clk_cnt)
zeroone : temp <= {mul2[1:0],1'b0};
twothree : temp <= mul2[3:1];
fourfive : temp <= mul2[5:3];
sixseven : temp <= mul2[7:5];
default : temp <= 0;
endcase
end
always @(posedge clk) begin
if (clk_cnt == 3'b100) begin//如果节拍到4就让部分积归0,此时已经完成一次计算了
A <= 0;
end else case (temp)
3'b000,3'b111 : begin//这些是从高位到低位的判断,别看反了噢
A <= A + 0;
end
3'b001,3'b010 : begin//加法操作使用补码即可,倍数利用左移解决
A <= A + ({{8{mul1[`size-1]}},mul1} << 2*(clk_cnt-1));
end
3'b011 : begin
A <= A + ({{8{mul1[`size-1]}},mul1} << 2*(clk_cnt-1) + 1);
end
3'b100: begin//减法操作利用“负补码”改成加法操作,倍数利用左移解决
A <= A + ({{8{bmul1[`size-1]}},bmul1} << 2*(clk_cnt-1) + 1);
end
3'b101,3'b110 : begin
A <= A + ({{8{bmul1[`size-1]}},bmul1} << 2*(clk_cnt-1));
end
default: A <= 0;
endcase
end
//当节拍到4的时候写入结果寄存器。
assign res = (clk_cnt == 3'b100) ? A : 0;
endmodule -
请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
将
busy信号输入阻塞判断单元SU,如果E级乘除槽busy,或者正在执行cal_hl指令,且F级指令为乘除槽相关的cal_hl,write_hl,read_hl指令,则无脑进行阻塞,知道乘除槽完成运算,将busy信号置0 -
请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
没什么好处,感觉不如我原来的方案()还带来了一些费劲的读写不一致的问题。
可能的好处就是方便扩展指令,支持如对3个字的读写,对按字节、半字、字的读写更统一。
-
请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
不是统一字节,需要进行相关的移位操作。因为存储是按照32位存储的,一次取出一个字节32位是更高效的做法,按字和半字的读写需要进行相应的移位操作,使得效率降低。
-
为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
- 在CU单元对指令进行了按控制信号驱动的控制信号生成方法
- 对指令的操作统一,遵循同样的、可靠的数据通路,增加指令只需要更改几个控制信号即可
-
在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
没遇到。
测试样例按照8的思考进行测试,能够覆盖大部分的边界情况。
-
如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
手动构造样例:
对于测试,我的一个思考就是在不考虑中断之前,大数据、边界值其实没有很大的意义,最多需要考虑位宽究竟设置对了没有——因为对于
verilog这样的硬件描述语言来讲,溢出、数据错误往往都是来自于位宽没有对准、位宽错误,数据的范围就是位宽的范围。基于这样的认识,测试所需要的事其实就是两件:数据有没有放对寄存器、内存,数据的位宽对不对。对于放对寄存器,这个很容易测,将数据在每个寄存器都放一遍,能放对就是得到了正确的结果。而去对于我所设计的CPU,不同质量的区别在于控制信号——都有着一样的数据通路,那么放对位置其实不用测很多次,R指令、I指令都各测一条实际上就可以达到测试效果。
对于位宽对不对的问题,只需要测试
fff+fff这种大位宽、有进位数据即可,达到了测试位宽+正确性的效果。 -
[P5、P6 选做] 请评估我们给出的覆盖率分析模型的合理性,如有更好的方案,可一并提出。
