
计组-实验-P7
CPU设计
概述
本次我设计的verilogMIPS微系统支持简单的异常、中断处理,支持执行COCO文档的中文指令集中的所有指令,共76条。
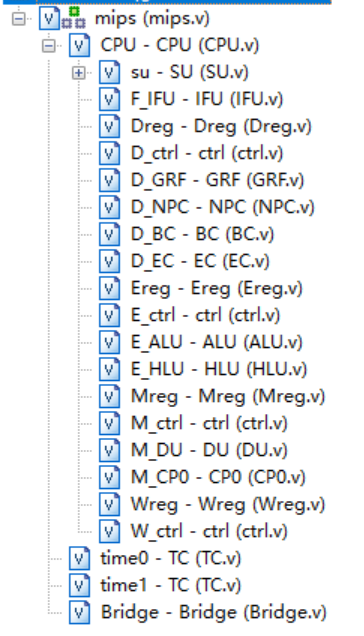
采用多个模块进行设计。所采用模块化设计为:
-
CPU
-
Stall Unit:阻塞单元,判断是否进行阻塞 -
IFU:指令单元,接受指令地址PC来给出当前周期处理的指令 -
GRF:寄存器模块,通过该模块统一进行32个寄存器的读写 -
NPC:计算下一条指令的地址,接受jump,branch等指令来支持跳转操作 -
Branch Control:分支跳转模块,判断是否该跳转 -
Error Control:Trap型异常控制模块,判断是否异常 -
ALU:进行运算操作,该ALU操作码为4为 -
DU:外村数据管理单元,管理和存储器数据之间的交互 -
CP0:负责进行简单的异常中断控制 -
ControlUnit:指令控制单元,通过接受op和func来发出指令,控制数据通路中的MUX
-
-
Bridge:负责与外设进行交互,管理数据的存取和使能信号
-
Timer:计时器外设,共有两个,可以释放外部中断信号
支持指令
支持76条指令,基本支持了中文指令集文档上的所有指令和基本指令集上的大部分指令。为:
- R指令:
add,addu,sub,subu,and,or,xor,nor,sll,sllv,srl,srlv,sra,srav,slt,sltu - I指令:
addi,addiu,slti,sltiu,andi,ori,xori,lui - 分支指令:
beq,beql,bne,bnel,bgez,bgezl,bgezal,bgezall,bgtz,bgtzl,blez,blezl,bltz,bltzl,bltzal,bltzall - J指令:
j,jr,jal,jalr - 存取存储器指令:
sw,lw,sh,sb,lh,lb,lhu,lbu - 乘除槽相关指令:
mfhi,mflo,mthi,mtlo,mult,multu,div,divu - 异常相关指令:
syscall,break,mtc0,mfc0 - Trap型异常相关指令:
teq,teqi,tne,tnei,tge,tgeu,tgei,tgeiu,tlt,tltu,tlti,tltiu
数据通路模块定义
IFU:指令单元
该模块在外置IM后丧失了原本的作用,目前的作用是进行PC指令的复位,作为PC和PCnext指令的中转站。负责接受PCnext,向外输出当前正在执行的指令在IM中的存储地址PC。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
Req |
I | 1 | 异常/中断信号,是否进入异常处理程序段 |
stall |
I | 1 | 阻塞信号 |
PCnext |
I | 32 | 下一条执行指令的地址 |
PC |
O | 32 | 当前正在执行指令的地址 |
功能定义
通过指令地址PC取得指令。
该组件支持同步复位,复位后输出的是地址为0x0000_3000处的指令。
NPC:指令地址单元
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
D_PC |
I | 32 | D级当前正在执行的指令 |
F_PC |
I | 32 | F级当前执行的指令 |
EPC |
I | 32 | 上一条异常/中断指令的地址 |
imm |
I | 26 | 对于J型指令时跳转的偏移量 |
offest |
I | 16 | 对于I型指令跳转时的偏移量 |
Req |
I | 1 | 当前是否进入异常/中断处理阶段 |
if_branch |
I | 1 | 是否进行I型指令的分支跳转 |
if_jump |
I | 1 | 是否进行J型指令的直接跳转 |
rs |
I | 32 | rs寄存器中的值 |
jumpSrc |
I | 1 | 跳转的地址选择是imm还是rs |
PC_next |
O | 32 | 输出计算后得到的下一个PC地址 |
功能定义
指令一共有四种情况:
- 不跳转,则
PCnext=F_PC+4 - 以
beq为代表的跳转,指令计算方式为PC和offest的计算,计算结果为PC_branch - J型指令跳转,指令计算有两种,通过
jumpSrc进行选择,计算结果为PC_jump- 以
j为代表的跳转,指令计算方式为立即数imm和PC的计算 - 以
jr为代表的跳转,指令计算方式为寄存器中储存的地址,即输入的rs寄存器中储存的值
- 以
- 进入异常/中断处理阶段,跳转到
0x0000_4180地址对应的指令处,没有延迟槽
由于延迟槽的引入,和跳转相关的指令都是在D_PC的基础上做运算,而正常情况下的PCnext则是F_PC+4,这是不一样的运算逻辑。
GRF:通用寄存器组
GRF为内置在CPU中的寄存器,也是在本CPU中最主要的数据存储单元。设有了两输出一输入端口。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 1 | 时钟信号 |
reset |
I | 1 | 复位信号,为异步复位 |
WE |
I | 1 | 写使能信号 |
A1 |
I | 5 | 读取编号1 |
A2 |
I | 5 | 读取编号2 |
A3 |
I | 5 | 写地址 |
WD |
I | 32 | 写数据 |
RD1 |
O | 32 | 输出读取编号1对应寄存器的值 |
RD2 |
O | 32 | 输出读取编号2对应寄存器的值 |
功能定义
实现了对寄存器堆的读写功能
ALU:计算单元
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
inA |
I | 32 | 输入数据1 |
inB |
I | 32 | 输入数据2 |
op |
I | 4 | 计算类型 |
shift |
I | 5 | 偏移量 |
result |
O | 32 | 计算结果 |
zero |
O | 1 | 计算结果是否为0 |
overflow |
O | 1 | 计算结果是否溢出 |
功能定义
实现了如下操作加、建、与、或、异或、与或、左逻辑移位、右逻辑移位、右算数移位、大小判断操作。对应ALU操作码如下:
| 操作码 | 操作 |
|---|---|
| 0000 | A+B |
| 0001 | A-B |
| 0010 | A and B |
| 0011 | A or B |
| 0100 | A xor B |
| 0101 | ~ ( A OR B ) |
| 0110 | B << shift |
| 0111 | B >> shift |
| 1000 | B >>> shift |
| 1001 | B << 16 |
| 1010 | A < B(有符号比较) |
| 1011 | A < B(无符号比较) |
HLU:乘除槽
对于乘除槽的引入,使得耗费较长时间的乘除运算可以单独进行,提高CPU流水的性能。
乘除槽中自带有LO和HI寄存器。在真实世界的CPU中,乘法操作需要5个时钟周期,除法操作需要10个时钟周期。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
clk |
I | 32 | 时钟信号 |
reset |
I | 1 | 同步复位信号 |
Req |
I | 1 | 是否为异常处理阶段 |
inA |
I | 32 | 输入数据1 |
inB |
I | 32 | 输入数据2 |
dst |
I | 1 | 目标是LO还是HI |
write |
I | 1 | 对目标寄存器的写使能信号 |
hluType |
I | 2 | 运算的种类 |
unSigned |
I | 1 | 是否进行无符号运算 |
busy |
O | 1 | 乘除槽是否忙碌 |
result |
O | 32 | 目标寄存器存储的数据 |
功能定义
实现了乘除操作,同时使用状态机模拟了真实乘除操作的耗时。
可以读写LO、HI寄存器。
| 操作码 | 操作 |
|---|---|
| 00 | 无操作 |
| 01 | 乘法 |
| 10 | 除法 |
并且,为了保证精确异常的实现,当处于异常/中断阶段时,原有的乘除指令不受影响,无法开启新的乘除槽相关指令
DU:存储器数据管理单元
对向存储器中数据的读写进行管理操作,负责给予使能和对数据进行一定的处理使满足规范。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
memData |
I | 32 | 原始的从内存中读出的原始数据 |
address |
I | 32 | 访问内存的地址 |
memIn |
I | 32 | 原始的欲写入内存的数据 |
store |
I | 1 | 是否为load型指令 |
load |
I | 1 | 是否为store型指令 |
WE |
I | 1 | 写使能 |
if_byte |
I | 1 | 是否按字进行读取 |
if_hlaf |
I | 1 | 是否按半字进行读取 |
load_extend |
I | 1 | 读取时是否进行符号扩展 |
memDataRead |
O | 32 | 处理后的读出内存的数据 |
memToWrite |
O | 32 | 处理后的写入内存的数据 |
byteen |
O | 4 | 对每个字的写使能信号 |
adel |
O | 1 | 是否有Adel型异常 |
ades |
O | 1 | 是否有Ades型异常 |
功能定义
对于数据的处理:由于引入了按字节使能的信号,所以需要对数据进行相应的移位操作来匹配字节。
- 写入:原始的数据,如0x00000012,如果想要写入3($0)的位置,则需要将数据左移16位进行匹配
- 读出:同样对按字、半字访问进行了相应的移位,同时按照
load_extend进行了相应的符号扩展 - 生成了按字节的写使能信号:对课程组的妥协,我觉得是愚蠢的操作
Branch Control:分支控制
专门用来处理分支型指令,判断是否要进行分支跳转
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 具体的信号类型 |
rt |
I | 5 | rt的地址 |
rd1 |
I | 32 | 数据输入1 |
rd2 |
I | 32 | 数据输入2 |
if_branch |
O | 32 | 是否进行跳转 |
功能定义
对于分支,有以下这么几种情况:
beq和bne,通过读取GRF得到的rd1和rd2的数值大小关系进行比较- 和0比较的分支
bgez和bltz的op字段相同,靠rt字段进行区分- 在该模块中直接进行数值比较,需要注意的是应该为有符号数
Error Control:Trap型异常控制
专门用来处理Trap型异常指令,判断是否为Trap型异常
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
op |
I | 6 | 具体的信号类型 |
rt |
I | 5 | rt的地址 |
rd1 |
I | 32 | 数据输入1 |
rd2 |
I | 32 | 数据输入2 |
if_branch |
O | 32 | 是否进行跳转 |
功能定义
对于分支,有以下这么几种情况:
beq和bne,通过读取GRF得到的rd1和rd2的数值大小关系进行比较- 和0比较的分支
bgez和bltz的op字段相同,靠rt字段进行区分- 在该模块中直接进行数值比较,需要注意的是应该为有符号数
Stall Unit:阻塞控制单元
通过接受CPU中的D级、E级、M级三级的指令,判断Tuse和Tnew,计算是否要进行阻塞。如果不阻塞,则进行无脑转发,以提高CPU的运行效率,减少考可能的阻塞(无脑阻塞理论参考了qsgg的博客))
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
D_inStr |
I | 32 | D级正在执行的指令 |
E_inStr |
I | 32 | E级正在执行的指令 |
M_inStr |
I | 32 | M级正在执行的指令 |
hl_busy |
I | 1 | 乘除槽是否进行操作 |
stall |
O | 1 | 在当前CPU的运行情况下,是否进行阻塞 |
功能定义
结合流水线各级的指令情况,判断此时是否能够进行转发,否则进行阻塞流水线。
核心的判断逻辑为:
- ,则进行阻塞
- 当前乘除槽正在进行乘除运算或开始执行,且F级为乘除槽相关指令,则进行阻塞
对于阻塞:
- D级流水寄存器写使能无效
- E级流水线寄存器清空
- 其余流水线寄存器正常执行
Control Unit:控制单元
个人认为是CPU最关键的部分,依靠指令的op和func部分生成控制逻辑,控制电路中的MUX单元,实现具体的运算。
端口定义
| 信号名 | 方向 | 位宽 | 具体翻译 |
|---|---|---|---|
inStr |
I | 32 | 指令 |
| GRF相关 | |||
regWrite |
O | 1 | GRF写使能信号 |
regDst |
O | 1 | GRF的写入地址是rt还是rd |
regRa |
O | 1 | GRF的写入地址是regSrc还是31 |
regSrc |
O | 1 | GRF的写入数据来源是ALU还是内存 |
regPc |
O | 1 | GRF的写入数据来源是是否为PC+8 |
regCp0 |
O | 1 | GRF的写入数据来源是是否为CP0中的寄存器的数据 |
aluSrc |
O | 1 | ALU的输入数据2来自rt还是指令中的offest字段 |
extendType |
O | 1 | 对指令中offest字段extand的方式是sign还是zero |
shiftSrc |
O | 1 | ALU的shift输入来自rs还是指令中的shamt字段 |
memWrite |
O | 1 | DM的写使能信号 |
jump |
O | 1 | NPC的if_jump信号 |
jumpSrc |
O | 1 | NPC的jumpSrc输入来自指令中的imm字段还是rs |
aluControl |
O | 4 | ALU的操作码 |
if_signed |
O | 1 | ALU的计算是否是有符号的(不忽略溢出) |
if_byte |
O | 1 | 对内存的读取是否按字 |
if_half |
O | 1 | 对内存的读取是否按半字 |
load_extend |
O | 1 | 对内存读取结果是否进行符号扩展 |
| 乘除槽相关 | |||
resultSrc |
O | 1 | D级结果的来源是ALU还是HLU |
hluDst |
O | 1 | HLU操作的对象是LO还是HI |
hluWrite |
O | 1 | 对HLU的写使能 |
hluUnSigned |
O | 1 | 对HLU的操作是否为无符号操作 |
hluControl |
O | 2 | HLU的操作码 |
| CP0相关 | |||
cp0Write |
O | 1 | CP0中寄存器的写使能信号 |
| 指令翻译相关 | |||
rs |
O | 5 | inStr的rs字段 |
rt |
O | 5 | inStr的rt字段 |
rd |
O | 5 | inStr的rd字段 |
dst |
O | 5 | 当前执行指令的目的寄存器是哪 |
| 指令分类相关 | |||
unknown |
O | 1 | 未知指令 |
calr |
O | 1 | 是否为寄存器相关计算 |
cali |
O | 1 | 是否为立即数相关计算 |
store |
O | 1 | 是否为写入内存 |
load |
O | 1 | 是否为读出内存 |
jump_imm |
O | 1 | 是否按立即数跳转 |
jump_reg |
O | 1 | 是否按寄存器跳转 |
jump_type |
O | 1 | 是否为跳转相关指令 |
branch_r |
O | 1 | 是否按寄存器分支 |
branch_i |
O | 1 | 是否按立即数分支 |
branch_type |
O | 1 | 是否为分支相关指令 |
shift_reg |
O | 1 | 是否按寄存器移位 |
shift_shamt |
O | 1 | 是否按shamt字段移位 |
cal_hl |
O | 1 | 是否为乘除槽计算 |
read_read |
O | 1 | 是否为读出乘除槽 |
write_hl |
O | 1 | 是否为写入乘除槽 |
eret |
O | 1 | 是否为eret指令 |
syscall |
O | 1 | 是否为syscall指令 |
break |
O | 1 | 是否为break指令 |
功能定义
根据指令的op字段和func字段,生成CPU的控制信号。
具体逻辑不表,给出对应的信号表:
| 0-1 | enable | rt-rd | regDst-31 | alu-mem | regSrc-PC+4 | regPC-CP0 | enable | rt-imm/off | alu-hilo | lo-hi | enable | sign-unsigned | sign-zero | rs-shamt | enable | sign-zero | enable | enable | enable | imm-rs | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| op | regWrite | regDst | regRa | regSrc | regPc | regCP0 | cp0Write | aluSrc | resultSrc | hluDst | hluWrite | hluUnsigned | hluControl | extendType | shiftSrc | memWrite | load_extend | if_half | if_byte | jump | jumpSrc | aluControl | alu | func | |
| add | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | + | 0000 | 100000 | ||||||
| addu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | + | 0000 | 100001 | ||||||
| sub | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | - | 0001 | 100010 | ||||||
| subu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | - | 0001 | 100011 | ||||||
| and | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | and | 0010 | 100100 | ||||||
| or | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | or | 0011 | 100101 | ||||||
| xor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | xor | 0100 | 100110 | ||||||
| nor | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | nor | 0101 | 100111 | ||||||
| sll | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | << | 0110 | 000000 | ||||||
| sllv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | << | 0110 | 000100 | ||||||
| srl | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | >> | 0111 | 000010 | ||||||
| sra | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 1 | 0 | x | x | x | 0 | x | >>> | 1000 | 000011 | ||||||
| srlv | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | >> | 0111 | 000110 | ||||||
| srav | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | >>> | 1000 | 000111 | ||||||
| slt | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | < | 1010 | 101010 | ||||||
| sltu | 000000 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | x | 0 | 0 | x | x | x | 0 | x | < | 1010 | |||||||
| addi | 001000 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | + | 0000 | |||||||
| addiu | 001001 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | + | 0000 | |||||||
| slti | 001010 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | < | 1010 | |||||||
| sltiu | 001011 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | < | 1010 | |||||||
| andi | 001100 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | and | 0010 | |||||||
| ori | 001101 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | x | x | x | 0 | x | or | 0011 | |||||||
| xori | 001110 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | x | x | x | 0 | x | xor | 0100 | |||||||
| lui | 001111 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | <-16 | 1001 | 101011 | ||||||
| beq | 000100 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | - | 0001 | |||||||
| bgez | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |||||||
| bgtz | 000111 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |||||||
| blez | 000110 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |||||||
| bltz | 000001 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | |||||||
| bne | 000101 | 0 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | x | x | x | 0 | x | - | 0001 | |||||||
| j | 000010 | 0 | x | 0 | x | 0 | x | x | x | x | 0 | x | x | x | 1 | 0 | x | x | 001000 | ||||||
| jr | 000000 | 0 | x | 0 | x | 0 | x | x | x | x | 0 | x | x | x | 1 | 1 | x | x | |||||||
| jal | 000011 | 1 | 1 | 1 | 0 | 1 | x | x | x | x | 0 | x | x | x | 1 | 0 | x | x | 001001 | ||||||
| jalr | 000000 | 1 | 1 | 0 | x | 1 | x | x | x | x | 0 | x | x | x | 1 | 1 | x | x | |||||||
| sw | 101011 | 0 | x | x | x | 0 | 1 | 0 | 0 | 0 | 1 | x | 0 | 0 | 0 | x | + | 0000 | |||||||
| sh | 101001 | 0 | x | x | x | 0 | 1 | 0 | 0 | 0 | 1 | x | 1 | 0 | 0 | x | + | 0000 | |||||||
| sb | 101000 | 0 | x | x | x | 0 | 1 | 0 | 0 | 0 | 1 | x | 0 | 1 | 0 | x | + | 0000 | |||||||
| lw | 100011 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x | 0 | 0 | 0 | x | + | 0000 | |||||||
| lh | 100001 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | x | + | 0000 | |||||||
| lb | 100000 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | x | + | 0000 | |||||||
| lhu | 100100 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | x | + | 0000 | |||||||
| lbu | 100101 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | x | + | 0000 | |||||||
| mfhi | 000000 | 1 | 1 | 0 | 0 | 0 | x | 1 | 1 | 0 | 0 | 00 | x | 0 | 0 | x | x | x | 0 | x | x | x | 010000 | ||
| mflo | 000000 | 1 | 1 | 0 | 0 | 0 | x | 1 | 0 | 0 | 0 | 00 | x | 0 | 0 | x | x | x | 0 | x | x | x | 010010 | ||
| mthi | 000000 | 0 | x | x | x | x | x | 0 | 1 | 1 | 0 | 00 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | 010001 | ||
| mtlo | 000000 | 0 | x | x | x | x | x | 0 | 0 | 1 | 0 | 00 | 0 | 0 | 0 | x | x | x | 0 | x | x | x | 010011 | ||
| mult | 000000 | 0 | x | x | x | x | x | 0 | 0 | 0 | 0 | 01 | 011000 | ||||||||||||
| multu | 000000 | 0 | 0 | 0 | 0 | 1 | 01 | 011001 | |||||||||||||||||
| div | 000000 | 0 | 0 | 0 | 0 | 0 | 10 | 011010 | |||||||||||||||||
| divu | 000000 | 0 | 0 | 0 | 0 | 1 | 10 | 011011 | |||||||||||||||||
| mtc0 | 0 | ||||||||||||||||||||||||
| mfc0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | x | x | x | x | x | x | x | x | 0 | 0 | x | x | 0 | x | x | |||
| eret | 0 | 1 | |||||||||||||||||||||||
| syscall | 000000 | 001100 | |||||||||||||||||||||||
| break | 000000 | 001101 |
流水寄存器
共有Dreg,Ereg,Mreg,Wreg四个流水寄存器,存储了当前流水阶段执行所需的全部数据,输入输出有差别但大体类似,核心思想相同,不再赘述。
Dreg,Ereg支持阻塞功能,Dreg作为延迟槽还支持清空延迟槽功能。
CPU测试
对于测试的认识
对于测试,我的一个思考就是在不考虑中断之前,大数据、边界值其实没有很大的意义,最多需要考虑位宽究竟设置对了没有——因为对于verilog这样的硬件描述语言来讲,溢出、数据错误往往都是来自于位宽没有对准、位宽错误,数据的范围就是位宽的范围。基于这样的认识,测试所需要的事其实就是两件:数据有没有放对寄存器、内存,数据的位宽对不对。
对于放对寄存器,这个很容易测,将数据在每个寄存器都放一遍,能放对就是得到了正确的结果。而去对于我所设计的CPU,不同质量的区别在于控制信号——都有着一样的数据通路,那么放对位置其实不用测很多次,R指令、I指令都各测一条实际上就可以达到测试效果。
对于位宽对不对的问题,只需要测试fff+fff这种大位宽、有进位数据即可,达到了测试位宽+正确性的效果。
测试方式
按照我对测试的理解,手动生成测试数据,在迭代开发钟工作量其实并不大。
使用python程序进行一键运行,并使用标准库difflib进行可视化比较
- 通过python程序将MIPS汇编程序
test.asm编译并运行,形成16进制机器码code.txt和标准输出mips_out.txt。 - 使用命令行运行ise,得到工程文件的输出
verilog_out.txt。然后我们对两个输出文件进行比较,得出比较结果。 - 通过标准库
difflib运行得到可视化的输出比较保护视力
1 | import os |
思考题
-
请查阅相关资料,说明鼠标和键盘的输入信号是如何被 CPU 知晓的?
键盘和鼠标本质上都是输入设备,其自身的内部有一些微处理器来控制自己与主机之间的信息交互。
每个设备通过驱动程序释放中断信号,指引处理器处理相应的输入信息。
-
请思考为什么我们的 CPU 处理中断异常必须是已经指定好的地址?如果你的 CPU 支持用户自定义入口地址,即处理中断异常的程序由用户提供,其还能提供我们所希望的功能吗?如果可以,请说明这样可能会出现什么问题?否则举例说明。(假设用户提供的中断处理程序合法)
在CPU实现中,异常处理程序的跳转是由硬件进行管理的,如果自定义入口,则需要修改硬件来达到跳转效果,否则执行类似于跳转指令,会有延迟槽,无法达到精确异常的效果。
并且,将异常处理地址向程序员暴露后,会使得处理器的设计复杂性大大提升,增加程序员的工作量。
-
为何与外设通信需要 Bridge?
教程中其实说的很明白了,外设的种类可以是无限的,而地址空间是有限的,所以需要进行管理,通过Bridge提供一个接口,来进行和数据之间通信的中介。
-
请阅读官方提供的定时器源代码,阐述两种中断模式的异同,并分别针对每一种模式绘制状态移图。
- 计数模式0:当计数器倒计数为0 后,计数器停止计数,此时控制寄存器中的使能Enable自动变为0。当使能Enable 被设置为1 后,初值寄存器值再次被加载至计数器,计数器重新启动倒计数。可以用于产生定时脉冲。
- 计数模式1:当计数器倒计数为0 后,初值寄存器值被自动加载至计数器,计数器继续倒计数。可以用于产生定时脉冲。

-
倘若中断信号流入的时候,在检测宏观 PC 的一级如果是一条空泡(你的 CPU 该级所有信息均为空)指令,此时会发生什么问题?在此例基础上请思考:在 P7 中,清空流水线产生的空泡指令应该保留原指令的哪些信息?
不会发生什么问题,
nop指令即为不执行,不会对寄存器和存储器进行修改。应该保留PC值,由于在Req信号有效时,通过将流水寄存器的PC值不进行复位,使得达到精确异常的效果。使得回到EPC时依然是精确的。
-
为什么
jalr指令为什么不能写成jalr $31, $31?如果
jalr $31 $31的延迟槽内发生异常或需要响应中断。那么$31寄存器的值已经被jalr改变,但是处理异常结束后,会再次执行jalr指令,这就会跳转到不正确的PC地址。 -
[P7 选做] 请详细描述你的测试方案及测试数据构造策略。
见CPU测试章节
